
Introduction:
Performance tuning in BW can be done mainly in three different stages: modelling, extraction and reporting. Each of these areas is important for smooth functioning of the a data warehouse.
Apart from technical landscape and hardware considerations from Data warehouse management perspective Performance Optimization within SAP BW can be broadly categorized into the below areas:
1. Optimization of Data Warehouse/ ETL process
2. Optimization of the Report run times
The above two aspects have been discussed below in detail.
1. Query Performance
2. Loading Performance
1. Query Performance
2. Loading Performance
Performance Optimization of Data warehouse/ ETL process:
We have three layers in BW back-end to consider.
- Collection and Extraction Layer
- Transformation Layer
- Staging and Storage layer
Collection and Extraction Layer –
Data collection is performed on the source system. Prior to any data-upload activities, the extraction mechanisms and data source have to be configured on the relevant source system. The three types of data sources are SAP R/3 source systems, non-SAP source systems (such as an Oracle database), and flat-file source systems (such as a Microsoft Excel file). When extracting data from SAP R/3 source systems, you may use either Business Content extractors (which you can enhance) or generic extractors.
Business Content Extractors:
- Identify long-running extraction processes on the source system :Extraction processes are performed by several extraction jobs running on the source system. The runtime of these jobs affects the performance. Use transaction code SM37 -> Background Processing Job Management to analyze the runtimes of these jobs. If the runtime of data collection jobs lasts for several hours schedule these jobs to run more frequently. This way less data is written into update tables for each run and extraction performance increases.
- Identify high run-times for ABAP code, especially for user exits :The quality of any custom ABAP programs used in data extraction affects the extraction performance. Use transaction code SE30 -> ABAP/4 Run-time Analysis and then run the analysis for the transaction code RSA3 Extractor Checker. The system then records the activities of the extraction program so you can review them to identify time-consuming activities. Eliminate those long running activities or substitute them with alternative program logic.
- Identify expensive SQL statements:
If database runtime is high for extraction jobs, use transaction code ST05 -> Performance Trace. On this screen select ALEREMOTE user and then select SQL trace to record the SQL statements. Identify the timeconsuming sections from the results. If the data selection times are high on a particular SQL statement, index the DataSource tables to increase the performance of selection. While using ST05 make sure that no other extraction job is running with ALEREMOTE user.
- Balance loads by distributing processes onto different servers if possible :If your site uses more than one BW application server, distribute the extraction processes to different servers using transaction code SM59 -> Maintain RFC Destination. Load balancing is possible only if the extraction program allows the option.
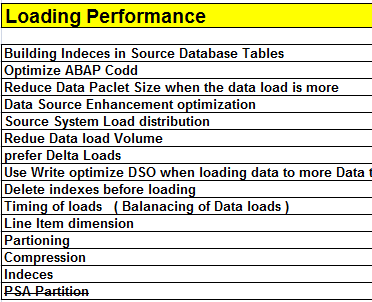
- Set optimum parameters for data-packet size :Packet size affects the number of data requests to the database. Set the data-packet size to optimum values for an efficient data-extraction mechanism. To find the optimum value, start with a packet size in the range of 50,000 to 100,000 and gradually increase it. At some point, you will reach the threshold at which increasing packet size further does not provide any performance increase. To set the packet size, use transaction code SBIW -> BW IMG Menu on the source system. To set the data load parameters for flat-file uploads, use transaction code RSCUSTV6 in BW.
- Use TRFC (PSA) as transfer method instead of IDocs :
If possible, always use TRFC (PSA) as the transfer method instead of IDocs. If IDocs have to be used, keep the number of data IDocs as low as possible. It’s recommended to keep an IDoc size of between 10000 (Informix) and 50000 (Oracle, MS SQL Server). To upload from a file, set this value in Transaction RSCUSTV6. To upload from an R/3 system, set this value in R/3 Customizing (SBIW -> General settings -> Control parameters for data transfer).
- Build indexes on DataSource tables based on selection criteria :Indexing DataSource tables improves the extraction performance, because it reduces the read times of those tables.
- Use the new V3 collection methods (Applicable for LO Extractors) :The V3 update method is a new extraction technique used in the R/3 logistics area. It provides delta capabilities for BW system with specific extraction times in the background. With the V3 extraction mechanisms, you can define the period of the delta collection jobs on the OLTP system. This reduces the overhead on the source system and the amount of data to be processed. Unlike the old LIS extraction mechanisms, the V3 mechanism also allows you to collect only BW-relevant data, further reducing the extraction-related workload on the OLTP source system.
- Schedule and run V3 collection jobs for different DataSources in parallel (Applicable for LO Extractors) :
This reduces the overall time required for the collection jobs. You can schedule these jobs with transaction code SM37 in the source system.
Generic Extractors :
- Execute collection jobs in parallel. Like the Business Content extractors, generic extractors have a number of collection jobs to retrieve relevant data from DataSource tables. Scheduling these collection jobs to run in parallel reduces the total extraction time, and they can be scheduled via transaction code SM37 in the source system.
- Schedule and run InfoPackages in parallel. Break up your data selections for InfoPackages and schedule the portions to run in parallel. This parallel upload mechanism sends different portions of the data to BW at the same time, and as a result the total upload time is reduced. You can schedule InfoPackages in the Administrator Workbench.
- Create secondary indexes for selection fields. Building secondary indexes on the tables for the selection fields optimizes these tables for reading, reducing extraction time. If your selection fields are not key fields on the table, primary indexes are not much of a help when accessing data. In this case it is better to create secondary indexes with selection fields on the associated table using ABAP Dictionary to improve better selection performance.
For Flat File Uploads:
- If possible, load the data from a file on the application server and not from the client workstation as this reduces the network load. This also allows to load in batch.
- It’s suggested to use a fixed record length when data needs to be loaded from a file (ASCII file). For a CSV file, the system only carries out the conversion to a fixed record length during the loading process.
- When large data quantities are to be loaded from a file, it’s recommended to split the file into several parts with files of the same size as there are CPUs. You can then load these files simultaneously to the BW system in several requests. To do this, you require a fast RAID.
Transformation Layer –
- Analyze upload times to the PSA and identify long-running uploads :When you extract the data using PSA method, data is written into PSA tables in the BW system. If your data is on the order of tens of millions, consider partitioning these PSA tables for better performance, but pay attention to the partition sizes. Partitioning PSA tables improves data-load performance because it's faster to insert data into smaller database tables. Partitioning also provides increased performance for maintenance of PSA tables — for example, you can delete a portion of data faster. You can set the size of each partition in the PSA parameters screen, in transaction code SPRO or RSCUSTV6, so that BW creates a new partition automatically when a threshold value is reached.
- Debug any routines in the transfer and update rules or transformations and eliminate single selects from the routines :
Using single selects in custom ABAP routines for selecting data from database tables reduces performance considerably. It is better to use buffers and array operations. When you use buffers or array operations, the system reads data from the database tables and stores it in the memory for manipulation, improving performance. If you do not use buffers or array operations, the whole reading process is performed on the database with many table accesses, and performance deteriorates. Also, extensive use of library transformations in the ABAP code reduces performance; since these transformations are not compiled in advance, they are carried out during run-time.
Staging and Storage Layer –
- Always upload master data before transactional data :
When you upload the associated master data in advance, the system updates the surrogate ID (SID) tables. It’s prescribed to load master data first in the order of attributes, texts and hierarchies. This ensures SIDs are generated before transaction data is loaded. With the SID tables up-to-date, transaction data uploads become smoother, because if the system cannot find master data for a record during the transaction data upload, it first updates the SID tables and then inserts the record. This extra step reduces performance.
For loading large quantities of data the number range buffer for the info objects that are likely to have a high number of datasets has to be increased (SAP Note: 130253).
- Process data in parallel where possible :
The below points may be noted w.r.t parallelization for different load objects:
- Split up large requests using selection criteria in the Info Package. Schedule more than one info package with different selection options in each one instead of one.
- Avoid using parallel uploads for high volumes of data if hardware resources are constrained. Each Info Package uses one background process (if scheduled to run in the background) or dialog process (if scheduled to run online) of the application server, and too many processes could overwhelm a slow server.
- For files split up larger files into smaller files and load them in parallel.
- For DTPs use optimum data package size. The degree of parallelization of DTP can be also increased by increasing the number of parallel processes for a background job(s) of DTP.(Goto -> Settings for Batch Manager – Set the ‘Number of Processes’ ).
- When many DTPs are run in parallel with multiple processes each proper care needs to be taken to ensure that the jobs get distributed across different application servers as per the load balancing. This can be done by triggering the DTPs on specified Server or Server Group.(Note: The above parallelization settings can be done in BI Background Management (transaction RSBATCH) as well )
- Set control parameters (number of parallel processes, number of records per data packet, etc.) for an DSO before the data upload :
Also, deactivate the ‘SID Generation upon Activation’ option of DSO. If this option is active during the data load, the system reads the SID tables of relevant master data and links them to DSO table, and this reduces performance with the additional computations. Also use parallel upload mechanism that is available for DSO activation.
- Below are the recommendations for optimizing performance when loading and deleting data from InfoCube(s) / Aggregate(s):
- Drop the indexes before each data load and Regenerate them after the upload. Indexes on InfoCubes are optimized for reading data from the InfoCubes. If the indexes exist during the upload, BW reads the indexes and tries to insert the records according to the indexes, resulting in poor upload performance. You can automate the dropping and regeneration of the indexes through InfoPackage scheduling. You can drop indexes in the Manage InfoCube screen in the Administrator Workbench (Note: This is applicable for aggregates as well ).
- When loading large amounts of data to an InfoCube, you should increase the number range buffer for the dimensions in question. If possible, reset if after loading, This will prevent unnecessary memory consumption. For more information, see SAP Note 130253.
- When compressing an InfoCube's data for the first time, you should select no more than one request. After the first compression, you can select more than one request for the next one.If compression takes particularly long, you can optimize performance in the following case: If the data that you are loading to the InfoCube is disjunct with the data in other requests. By disjunct, we mean that all records in a request are different in at least one of the user-defined dimensions.For more information, see SAP Note 375132.
- Aggregates with fewer than 14 characteristics are created in such a way that each of these dimensions is a line item dimension and are purely filled from database. This improves performance when filling and rolling up.
- The Aggregate relevant process types like AGGRFILL (Initial filling), ATTRIBCHAN (Attribute change run), CHECKAGGR (Check aggregates during roll up), CONDAGGR (Compress aggregates), ROLLUP (Rollup) can be set to run in parallel in transaction RSBATCH. This helps in quicker processing of aggregates.
- For more guidelines on change run optimization refer the SAP Notes 176606, 555030 and 536223. If the InfoCube has a dimension with almost as many entries as the fact table itself, performance can be optimized by setting the Line Item or High Cardinality flag for this dimension.
- Generation of SID values for DSO :
The Generation of SID Values flag should not be set if the DSO is used for data storage purposes only as if the flag is set SIDs are created for all new characteristic values.
- Parallelization of parameters for activation, SID generation etc :
The required number of parallel processes for activation, SID generation and roll back can be set in individual DSO maintenance or transaction RSODSO_SETTINGS. Having more number of parallel processes for DSO activation/ SID generation and load balancing them on available application Servers/Server Groups appropriately improves performance.
- Archive aged or little-used data to reduce the data volume in your BW system :
IDoc (intermediate document) archiving improves the extraction and loading performance and can be applied on both BW and R/3 systems. In addition to IDoc archiving, data archiving is available for InfoCubes and ODS objects as of BW 3.0.
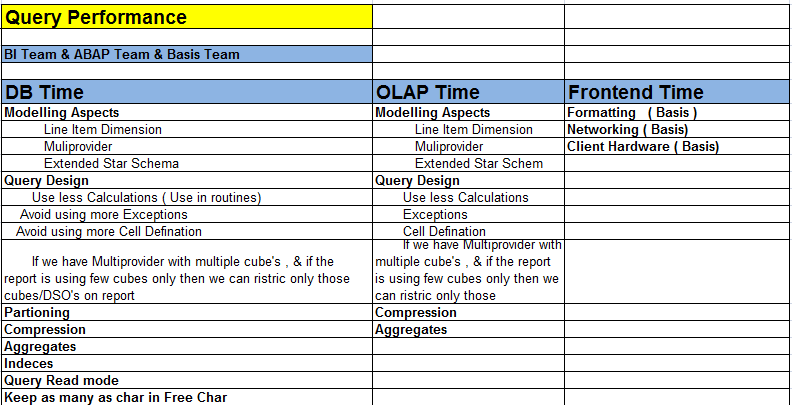
Performance Optimization of the Report runtimes:
- Design Guidelines :
The design of queries can have a significant impact on the performance. Sometimes long running queries are the result of poor design, not just the amount of data. There are a number of design techniques that developers can use to provide optimal query performance.
- Characteristics should be placed in the rows and key figures in the columns. A characteristic should only be used in the columns in certain circumstances (like time). Characteristics having potentially many values (such as 0MATERIAL) must not be added to the columns without a filter or variables. Alternatively, it can be integrated into the query as a free characteristic enabling it to be used in navigation.
- If a relatively detailed time characteristic, such as calendar day (0CALDAY) is added to the rows, the more aggregated time characteristics (such as calendar month (0CALMONTH)) and calendar year (0CALYEAR) should also be included in the free characteristics of the query. For most reports, a current period of time (current month, previous or current calendar year) is useful. For this reason, the use of variables is particularly relevant for time characteristics.
- Variables and drop down lists can improve query performance by making the data request more specific. This is very important for queries against Data Store Objects and InfoSets, which are not aggregated like InfoCubes.
- When queries are executed on an InfoSet with a large number of single value selections, some selections are often missing in the where condition of the generated SQL statement. This either results in poor system performance or in termination due to limitations given by the relevant database platform. This can be changed appropriately in RSCUSTV19.
- When using restricted key figures, filters or selections, try to avoid the Exclusion option if possible. Only characteristics in the inclusion can use database indexes. Characteristics in the exclusion cannot use indexes.
- When a query is run against a MultiProvider, all of InfoProviders in that MultiProvider are read. The selection of the InfoProviders in a MultiProvider query can be controlled by restricting the virtual characteristic 0INFOPROVIDER to only read the InfoProviders that are needed. In this way, there will be no unnecessary database reads.
- Keep the number of characteristics in the query as small as possible to help reduce the number of cells sent to the frontend. Avoid using cell definitions as far as possible as cell calculation by means of cell editor generates separate queries at query runtime.Hence, it should be used cautiously per the business requirement.
- Do not use Total Rows if not needed and also check codes for variables processed by customer exits.
- If possible defining calculated and restricted key figures at Info Provider level instead of Query level will improve query run time performance, but may add time for data loads.
- All calculations that need to be made before aggregation (such as currency translation) should take place when loading data if possible.
- Indexing on DSO Characteristics :
For queries based on DataStore objects, use selection criteria. If key fields are specified, the existing primary index is used. The more frequently accessed characteristic should appear on the left. If you have not specified the key fields completely in the selection criteria (you can check this in the SQL trace), you can improve the runtime of the query by creating additional indexes. However load performance is affected if there are too many secondary indexes.
- OLAP Caching :
The OLAP Cache can help with most query performance issues. For frequently used queries, the first access fills the OLAP Cache and all subsequent calls will hit the OLAP Cache and do not have to read the database tables. In addition to this pure caching functionality, the Cache can also be used to optimize specific queries and drill-down paths by ‘warming up’ the Cache; with this you fill the Cache in batch to improve all accesses to this query data substantially. (For more info refer SAP Note 859456 - Increasing performance using the cache)
- Aggregates :
Aggregates are materialized, pre-aggregated views on InfoCube fact table data. They are independent structures where summary data is stored within separate transparent InfoCubes. The purpose of aggregates is purely to accelerate the response time of queries by reducing the amount of data that must be read in the database for a given query navigation step. In the best case, the records presented in the report will exactly match the records that were read from the database. Aggregates can only be defined on basic InfoCubes for dimension characteristics, navigational attributes (time-dependent and time-independent) and on hierarchy levels (for time-dependent and time-independent hierarchy structures).
- Compression :
For performance reasons, and to conserve memory capacity, SAP recommends that you compress the InfoCube as soon as you know that the request has been loaded correctly and that it will not need to be deleted from the InfoCube again. Compression conserves memory space and improves system performance when data is being read. This helps in Query performance improvement .
- BI Accelerator (SAP BW on HANA is replacing this now):
It is a prepackaged hardware and software “appliance” that leverages SAP TREX search technology combined with hardware technology developed by Intel, for a state-of-the-art BI performance supercharger. The BI Accelerator indexes the information in the InfoCubes to create a highly compressed structure that can be loaded into memory whenever a user requests the data. The accelerator processes queries entirely in memory using high-performance aggregation techniques, and then delivers the results to the BI analytic engine in SAP NetWeaver for output to the user.
- Pre Calculation / Information Broadcasting :
These are set of techniques where we can distribute the workload of running the report to off-peak hours and have the report result set ready for very fast access to data. This reduces server load significantly and provides faster data access; data that goes to many web applications is re-used