
Why we need go for DataStore Objects ..?
There are several reasons why you use DSO before loading the data into cubes.
Provide delta functionality for the source systems that won't support delta. Like from flat files etc. This is also true for datasources which provide entire new record for changed records, without DSO (which only sends difference between before and after image values) data would double up and will be incorrect in infocubes.
DSO acts as a EDW layer so can reload the data into cubes (this can be due to change in business rules/logic or new cubes) directly from the DSO without the need to load all the way from the source system. This is even more crucial in cases where the old dat ais deleted, archived or not available in the source systems.
To store the data at more granular level. This is some times necessary because storing the data at very low level (say at document number level) in infocube will have performance issues with large data volumes. But the data at the level is required for occasional reporting needs. By creating RRI (Jump Reports from Summary to Detail) reports from Infocube to DSO we can avoid this performance issue.
Backup for fields needed in future : Business does not need some of the fileds right now but may need in future. DSO is useful in this scenario as you have this fields in DSO without the performance impact on the infocube and then can be loaded further into new/existing infocubes.
As a Data mart for several infocubes : DSO can feed and support delta for multiple infocubes from a single datasource. This is needed if you want do logical partitioning of the data in more than one infocube based on fical year, ledger type, currency type etc.
As a lookup table: You might need to use DSO as a lookup source to derive some fields while you load data into other cubes/dsos. You need DSO in this scenario, it is not ideal and very difficult to lookup on a infocube with two fact tables and 13 dimension tables.
Extract the data for downstream systems : You can write ABAP programs or allow downstream systems access the data direct from the DSO. The same is not easy with infocubes.
There are 3 Types of Data-Store Objects
1.Standard Data-Store object
The standard Data-Store object is filled with data during the extraction and load process in the BI system.
Structure
A standard DataStore object is represented on the database by three transparent tables:
Activation queue: Serves to save DataStore object data records that are to be updated, but that have not yet been activated. The data is deleted after the records have been activated.
Active data: A table containing the active data (A table).
Change log: Contains the change history for the delta update from the DataStore object into other data targets, such as DataStore objects or InfoCubes.
2. Direct Update DataStore
The DataStore object for direct update differs from the standard DataStore object in terms of how the data is processed
In the BI system, you can use a DataStore object for direct update as a data target for an analysis process..(SEM – Stragetic Enterprise Planning)
The DataStore object for direct update is also required by diverse applications, such as SAP Strategic Enterprise Management (SEM) for example, as well as other external applications.
We Can Manually Enter the Values by Using T.Code - RSINPUT
Use
DataStore objects for direct update ensure that the data is available quickly. The data is written to the DataStore object (possibly by several users at the same time) and reread as soon as possible.
Structure.
The DataStore object for direct update consists of a table for active data only. It retrieves its data from external systems via fill( RSINPUT)..
The load process is not supported by the BI system. The advantage to the way it is structured is that it is easy to access data. Data is made available for analysis and reporting immediately after it is loaded.
The DataStore object for direct update is also required by diverse applications, such as SAP Strategic Enterprise Management (SEM) for example, as well as other external applications.
We Can Manually Enter the Values by Using T.Code - RSINPUT
Use
DataStore objects for direct update ensure that the data is available quickly. The data is written to the DataStore object (possibly by several users at the same time) and reread as soon as possible.
Structure.
The DataStore object for direct update consists of a table for active data only. It retrieves its data from external systems via fill( RSINPUT)..
The load process is not supported by the BI system. The advantage to the way it is structured is that it is easy to access data. Data is made available for analysis and reporting immediately after it is loaded.
The concept of Write Optimized DSO was introduced in BI-7.0. Write Optimized DSO unlike Standard DSO has only one relational table, i.e. Active Table and moreover there is no SID generated in Write Optimized DSO, and hence loading the data from Data Source to Write Optimized DSO takes less time and acuires less disk space.
Business Case :
Require Data storage for storing detailed level of data with immediate reporting or further update facility. No over write functionality required.
Limitation of Standard DSO
- A standard DSO allows to store detailed level of information, However, activation process is mandatory.
- Reporting or further update is not possible until activation is completed.
Write Optimized DSO - Properties
- Primarily designed for initial staging of source system data
- Business rules are only applied when the data is updated to additional Info Providers.
- Stored in at most granular form
- Can be used for faster upload
- Records with the same key are not aggregated ,But inserted as new record, as every record has new technical key
- Data is available in active version immediately for further Processing
- There is no change log table and activation queue in it.
- Data is saved quickly.
- Data is stored in it at request level, same as in PSA table.
- Every record has a new technical key, only inserts.
- It is Partitioned on request ID (automatic).
- It allows parallel load, which saves time for data loading.
- It can be included in Process chain, and we do not need activation step for it.
- It supports archiving.
Write-Optimized DSO - Semantic Keys
Semantic Key identifies error in incoming records or Duplicate records .
Semantic Keys protects Data Quality such that all subsequent Records with same key are written into error stack along with incorrect Data Records.
To Process the error records or duplicate records , Semantic Group is defined in DTP.
Note : if we are sure there are no incoming duplicate or error records, Semantic Groups need not be defined.
Write Optimized DSO- Data Flow
1. Construct Data Flow model.
2. Create Data source
3. Create Transformation
4. Create Info Package
5. Create DTP
Write-Optimized-Settings
If we do not check the Check Box "Do not Check Uniqueness of Data ", the data coming from source is checked for duplication, i.e, if the same record (semantic keys) already exist in the DSO, then the current load is terminated.
If we select the check box , Duplicate records are loaded as a new record. There is no relevance of semantic keys in this case.
When Write Optimized DSO is Recommended?
- For faster data load., DSOs can be configured to be Write optimized
- When the access for Source system is for a small duration.
- It can be used as a first Staging layer.
- In cases where delta in Data Source is not enabled, we first load data into Write Optimized DSO and then delta load can be done to Standard DSO.
- When we need to load large volume of data into Info Providers, then WO DSO helps in executing complex transformations.
- Write Optimized DSO can be used to fetch history at request level, instead of going to PSA archive.
Write Optimised DSO - Functionality
- It contains only one table, i.e. active data table (DSO key: request ID, Packet No, and Record No)
- It does not have any change log table and activation queue.
- Every record in Wrtite Optimized DSO has a new technical key, and delta in it works record wise.
- In Wrtite Optimized DSO data is stored at request level like in PSA table.
- In Wrtite Optimized DSO SID is not generated.
- In Wrtite Optimized DSO Reporting is possible but it is not a good practice as it will effect the performance of DSO.
- In Wrtite Optimized DSO BEx Reporting is switched off.
- Wrtite Optimized DSO can be included in Info Set or Multiprovider.
- Due to Wrtite Optimized DSO performance is better during data load as there is no Activation step involved. The system generates a unique technical key
- The technical key in Wrtite Optimized DSO consists of the Request GUID field (0REQUEST), the Data Package field (0DATAPAKID) and the Data Record Number field (0RECORD).
Write-Optimized DSO-Points to Remember
Points to Remember :-
- Generally Write Optimized DSO is not prefered for reporting, but If we want to use it for reporting then it is recommended to defina a semantic in order to ensure the uniqueness of the data.
- Write-optimized DSOs can force a check of the semantic key for uniqueness when data is stored.
- If this option is active and if duplicate records are loaded with regard to semantic key, these are logged in the error stack of the Data Transfer Protocol (DTP) for further evaluation.
- If we need to use error stack in our flow then we need to define the semantic key in the DSO level.
- Semantic group definition is necessary to do parallel loads.
Write-Optimized DSO - Reporting
If we want to use write-optimized DataStore object in BEx queries(not preferred):
it is recommended to
1. Have a semantic key and
2. Ensure that the data is unique.
Here the Technical key is not visible for reporting, so it looks like any regular DSO
Business Case :
Require Data storage for storing detailed level of data with immediate reporting or further update facility. No over write functionality required.
Limitation of Standard DSO
- A standard DSO allows to store detailed level of information, However, activation process is mandatory.
- Reporting or further update is not possible until activation is completed.
Write Optimized DSO - Properties
- Primarily designed for initial staging of source system data
- Business rules are only applied when the data is updated to additional Info Providers.
- Stored in at most granular form
- Can be used for faster upload
- Records with the same key are not aggregated ,But inserted as new record, as every record has new technical key
- Data is available in active version immediately for further Processing
- There is no change log table and activation queue in it.
- Data is saved quickly.
- Data is stored in it at request level, same as in PSA table.
- Every record has a new technical key, only inserts.
- It is Partitioned on request ID (automatic).
- It allows parallel load, which saves time for data loading.
- It can be included in Process chain, and we do not need activation step for it.
- It supports archiving.
Write-Optimized DSO - Semantic Keys
Semantic Key identifies error in incoming records or Duplicate records .
Semantic Keys protects Data Quality such that all subsequent Records with same key are written into error stack along with incorrect Data Records.
To Process the error records or duplicate records , Semantic Group is defined in DTP.
Note : if we are sure there are no incoming duplicate or error records, Semantic Groups need not be defined.
Write Optimized DSO- Data Flow
1. Construct Data Flow model.
2. Create Data source
3. Create Transformation
4. Create Info Package
5. Create DTP
Write-Optimized-Settings
If we do not check the Check Box "Do not Check Uniqueness of Data ", the data coming from source is checked for duplication, i.e, if the same record (semantic keys) already exist in the DSO, then the current load is terminated.
If we select the check box , Duplicate records are loaded as a new record. There is no relevance of semantic keys in this case.
When Write Optimized DSO is Recommended?
- For faster data load., DSOs can be configured to be Write optimized
- When the access for Source system is for a small duration.
- It can be used as a first Staging layer.
- In cases where delta in Data Source is not enabled, we first load data into Write Optimized DSO and then delta load can be done to Standard DSO.
- When we need to load large volume of data into Info Providers, then WO DSO helps in executing complex transformations.
- Write Optimized DSO can be used to fetch history at request level, instead of going to PSA archive.
Write Optimised DSO - Functionality
- It contains only one table, i.e. active data table (DSO key: request ID, Packet No, and Record No)
- It does not have any change log table and activation queue.
- Every record in Wrtite Optimized DSO has a new technical key, and delta in it works record wise.
- In Wrtite Optimized DSO data is stored at request level like in PSA table.
- In Wrtite Optimized DSO SID is not generated.
- In Wrtite Optimized DSO Reporting is possible but it is not a good practice as it will effect the performance of DSO.
- In Wrtite Optimized DSO BEx Reporting is switched off.
- Wrtite Optimized DSO can be included in Info Set or Multiprovider.
- Due to Wrtite Optimized DSO performance is better during data load as there is no Activation step involved. The system generates a unique technical key
- The technical key in Wrtite Optimized DSO consists of the Request GUID field (0REQUEST), the Data Package field (0DATAPAKID) and the Data Record Number field (0RECORD).
Write-Optimized DSO-Points to Remember
Points to Remember :-
- Generally Write Optimized DSO is not prefered for reporting, but If we want to use it for reporting then it is recommended to defina a semantic in order to ensure the uniqueness of the data.
- Write-optimized DSOs can force a check of the semantic key for uniqueness when data is stored.
- If this option is active and if duplicate records are loaded with regard to semantic key, these are logged in the error stack of the Data Transfer Protocol (DTP) for further evaluation.
- If we need to use error stack in our flow then we need to define the semantic key in the DSO level.
- Semantic group definition is necessary to do parallel loads.
Write-Optimized DSO - Reporting
If we want to use write-optimized DataStore object in BEx queries(not preferred):
it is recommended to
1. Have a semantic key and
2. Ensure that the data is unique.
Here the Technical key is not visible for reporting, so it looks like any regular DSO
Created WODSO without checking “DO not Check Uniqueness of data” option:

Loaded 9 records:
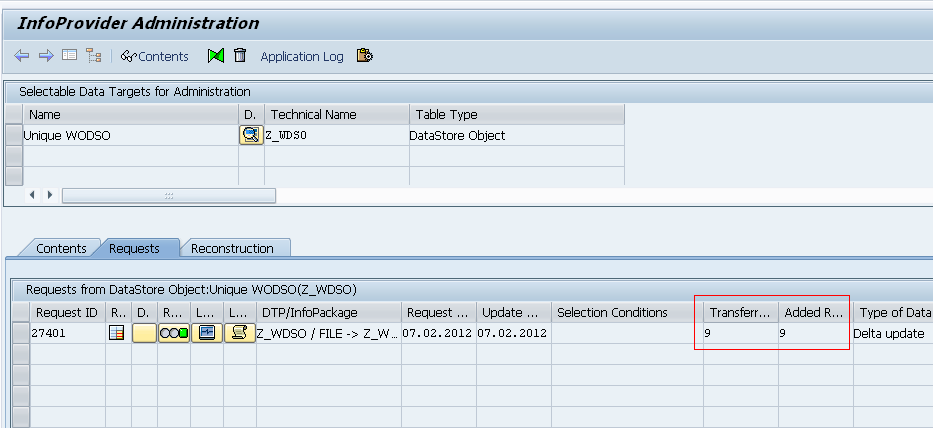
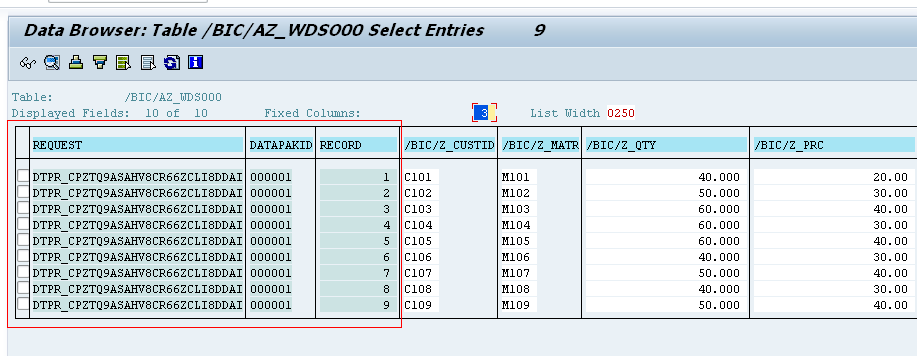
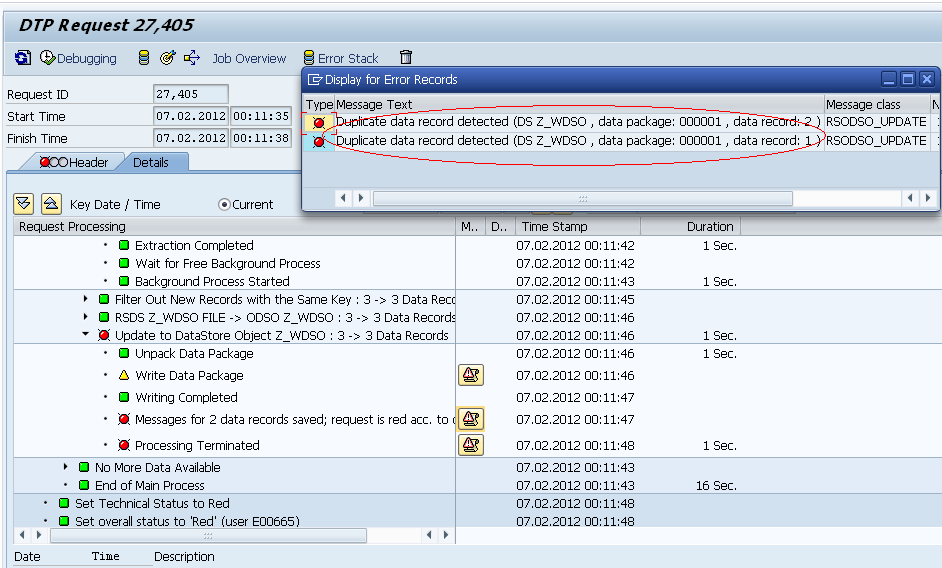
Loaded 3 modified records, at DTP level it will through an error saying “Duplicate data record detected…” as we have not checked the option “DO not Check Uniqueness of data” option, it will consider only the unique records.
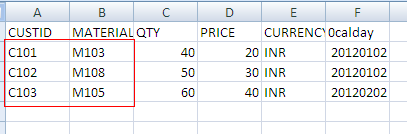
Again loaded with changing semantic key
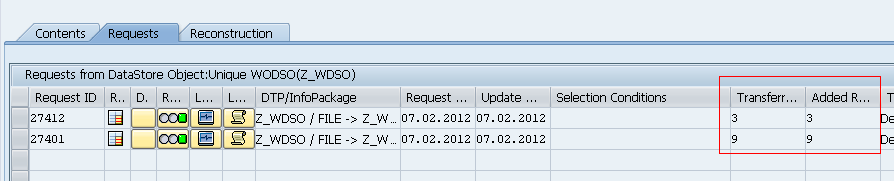

DSO with checking “DO not Check Uniqueness of data” option:

Loaded 8 records for the first load and 3 modified records for the second..

Here, we can see the duplicate records, the uniqueness of data is not maintained.
Write optimized DSO with Semantic key:
Scenario 1: select the setting ‘Do not check the uniqueness of data’ in the Write Optimized DSO.
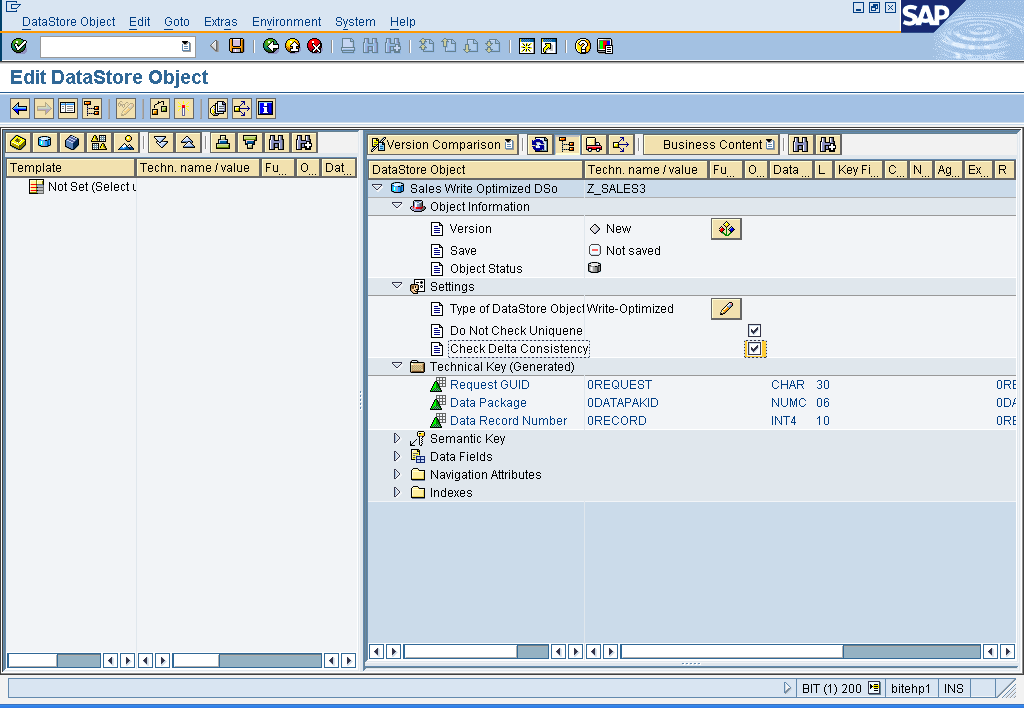
Note: Since data is written into Write-optimized DataStore active-table directly, you may not need to activate the request as is necessary with the standard DataStore object.
The system generates a unique technical key for the write-optimized DataStore object. The technical key consists of the Request GUID field (0REQUEST), the Data Package field (0DATAPAKID) and the Data Record Number field (0RECORD). Only new data records are loaded to this key.
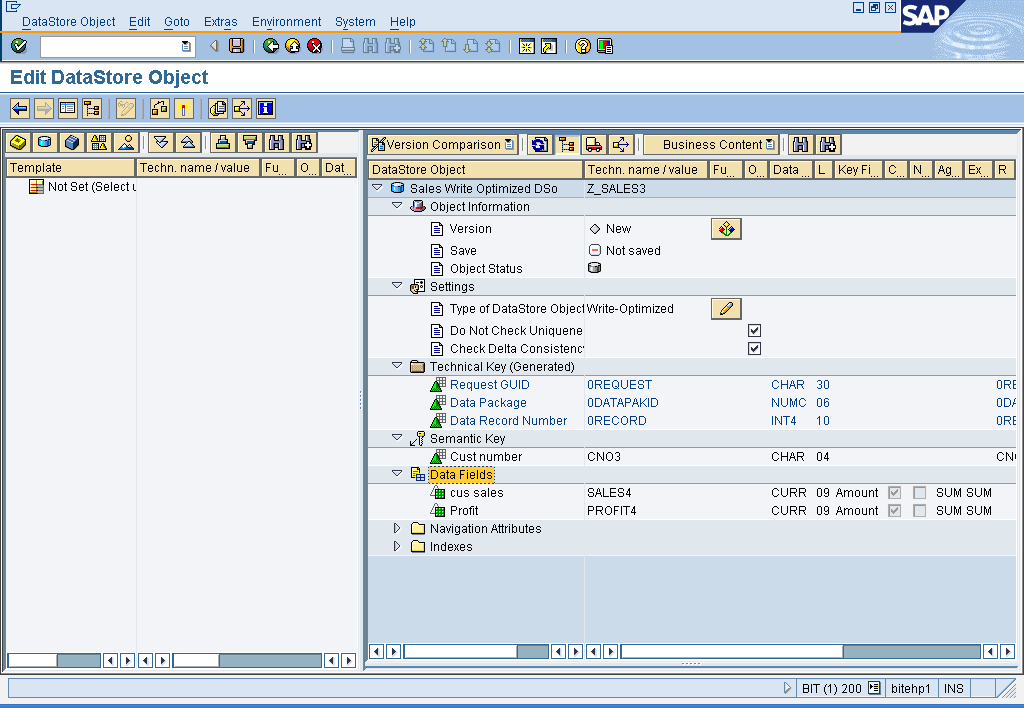
The standard key fields are not necessary with this type of DataStore object. Also you can define Write-Optimized DataStore without standard key.
If standard key fields exist anyway, they are called semantic keys so that they can be distinguished from the technical key.
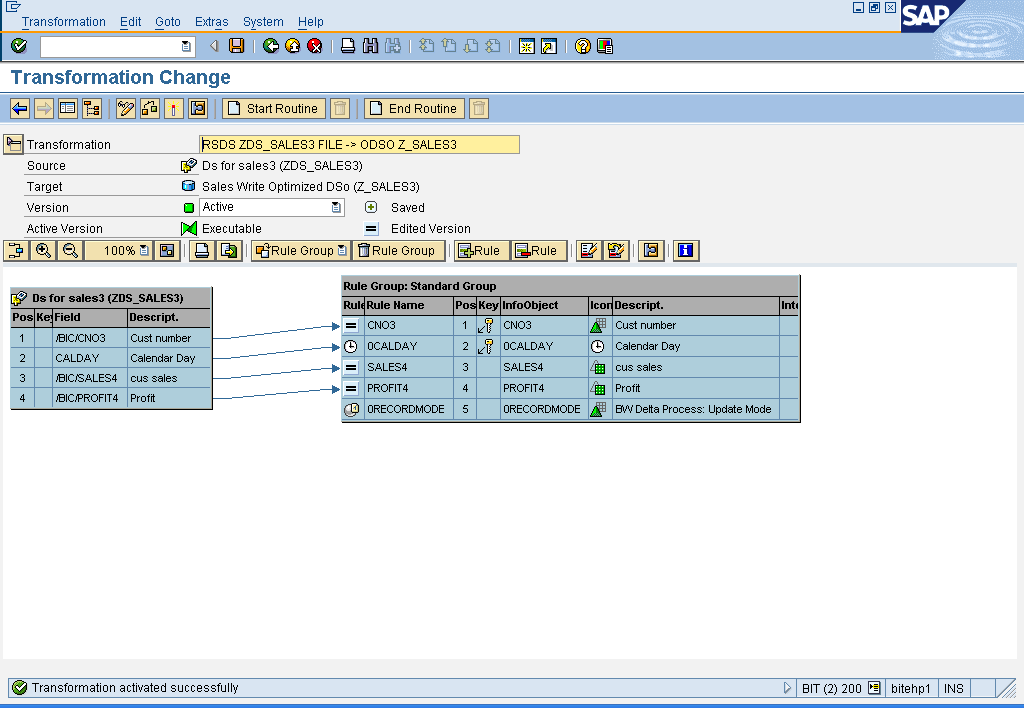
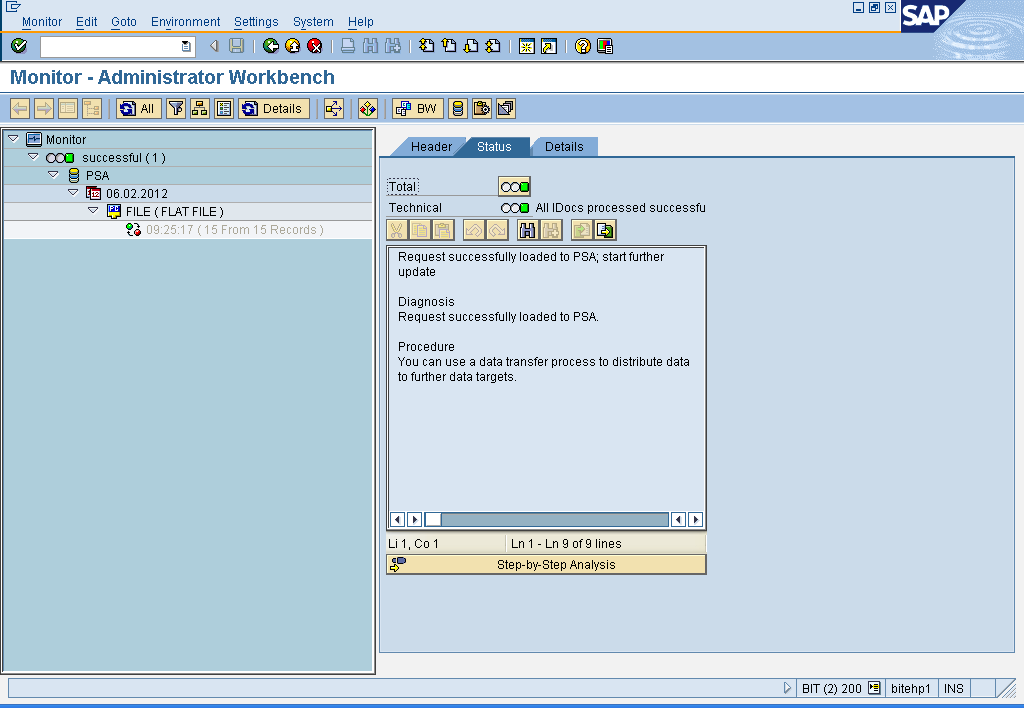

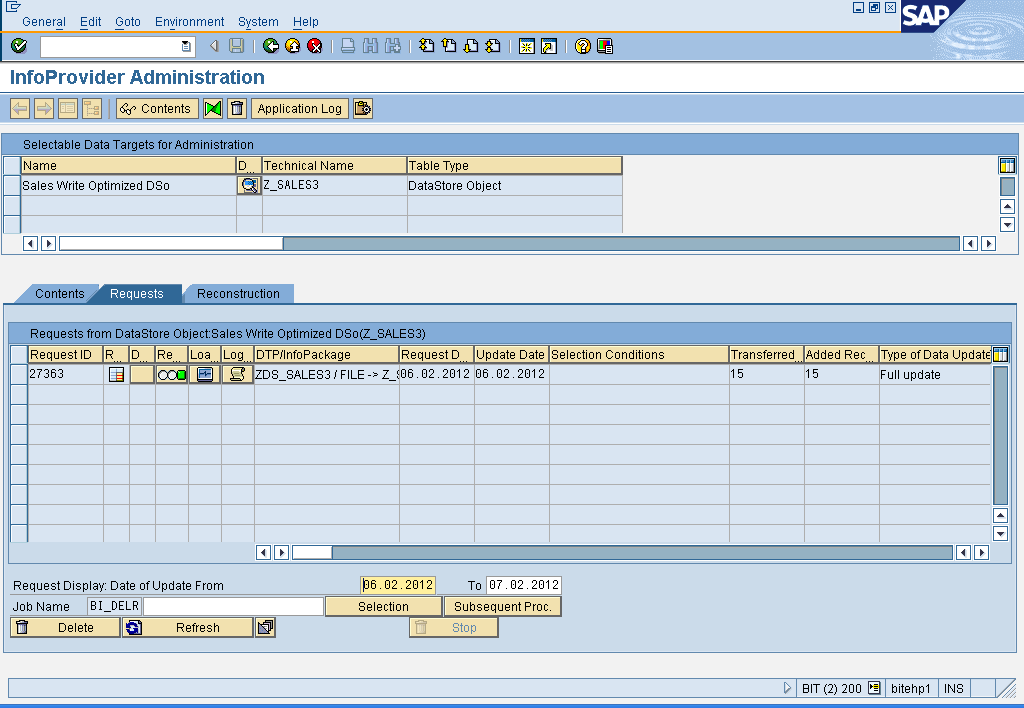
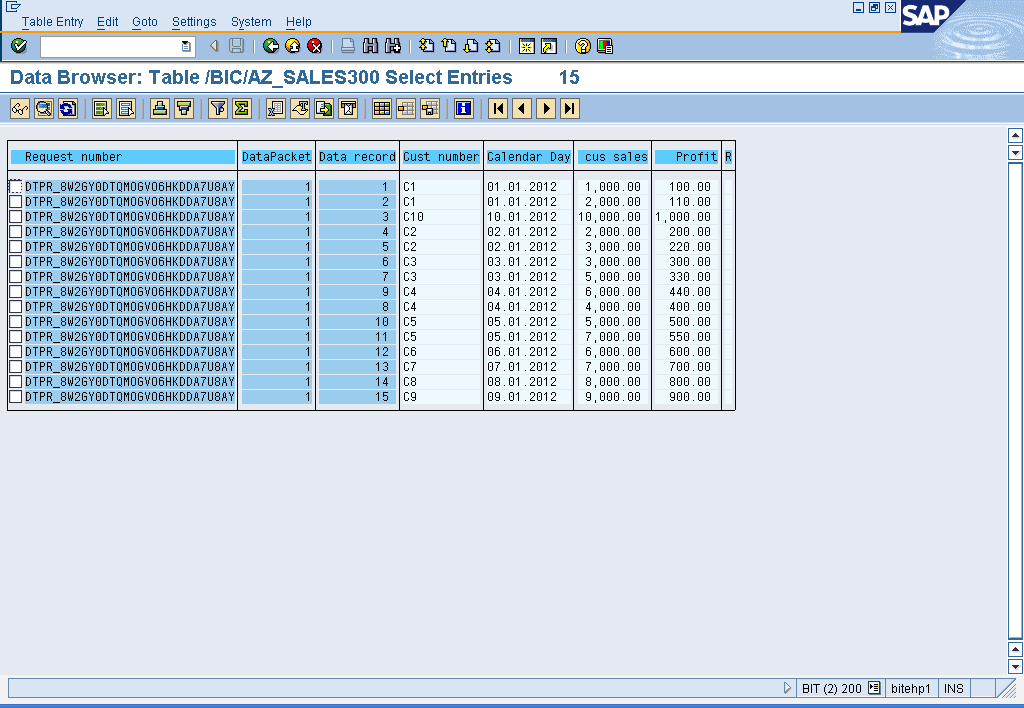
Note:
The loaded data is not aggregated; the history of the data is retained at request level. . If two data records with the same logical key are extracted from the source, both records are saved in the DataStore object. The record mode responsible for aggregation remains, however, the aggregation of data can take place later in standard DataStore objects.
If the setting – ‘do not check uniqueness of data’ is checked for the Write optimized DSO, the duplicate records with semantic key fields are treated as separate records and are written to the Write Optimized DSO.
Delta load:
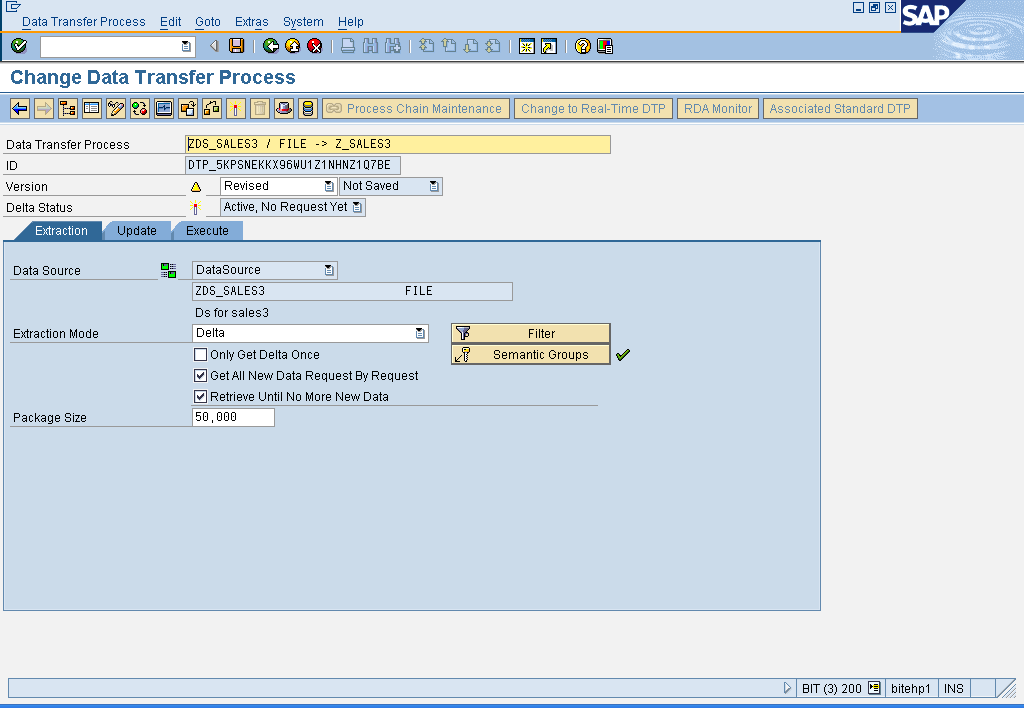
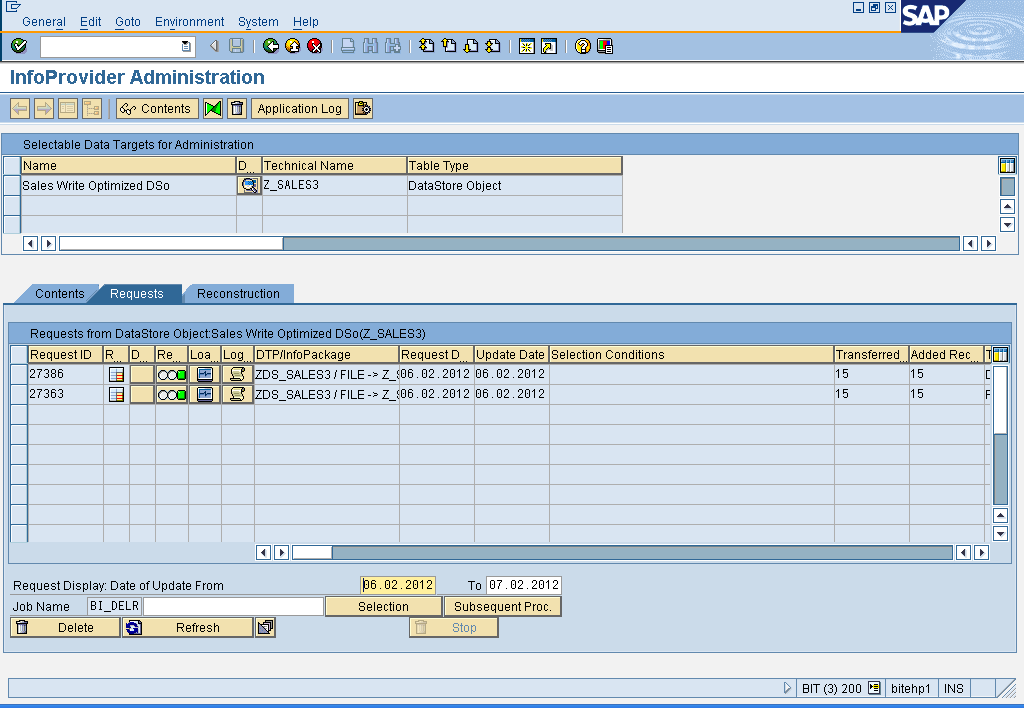
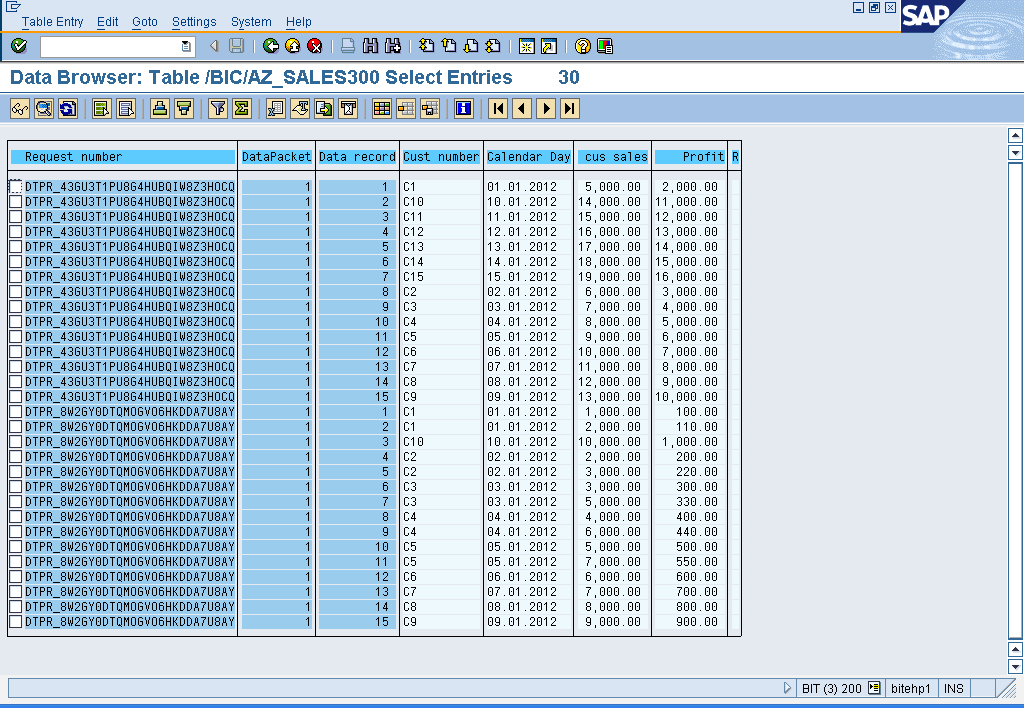
Note: Accepts duplicate values for semantic keys.
Observation:
- Where as if the setting – ‘do not check uniqueness of data’ is checked for the Write optimized DSO, the duplicate records with semantic key fields are treated as separate records and are written to the Write Optimized DSO.
Scenario 2:
Un-check the setting ‘do not check Uniqueness of data’.
Un-check the setting ‘do not check Uniqueness of data’.
Flat file contains 6 records, and 2 duplicate records.
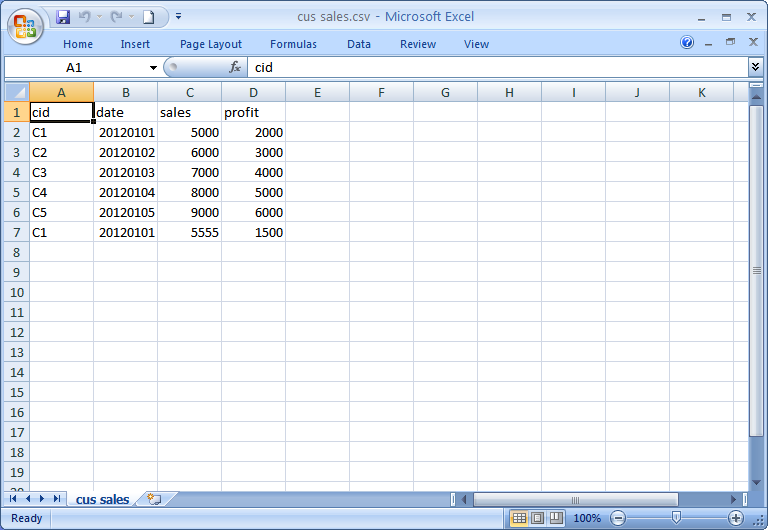
2. Create Write Optimize DSO, with symantic keys CUSTOMER NUMBER and 0CALDAY. Uncheck the setting ‘do not check Uniqueness of data’.
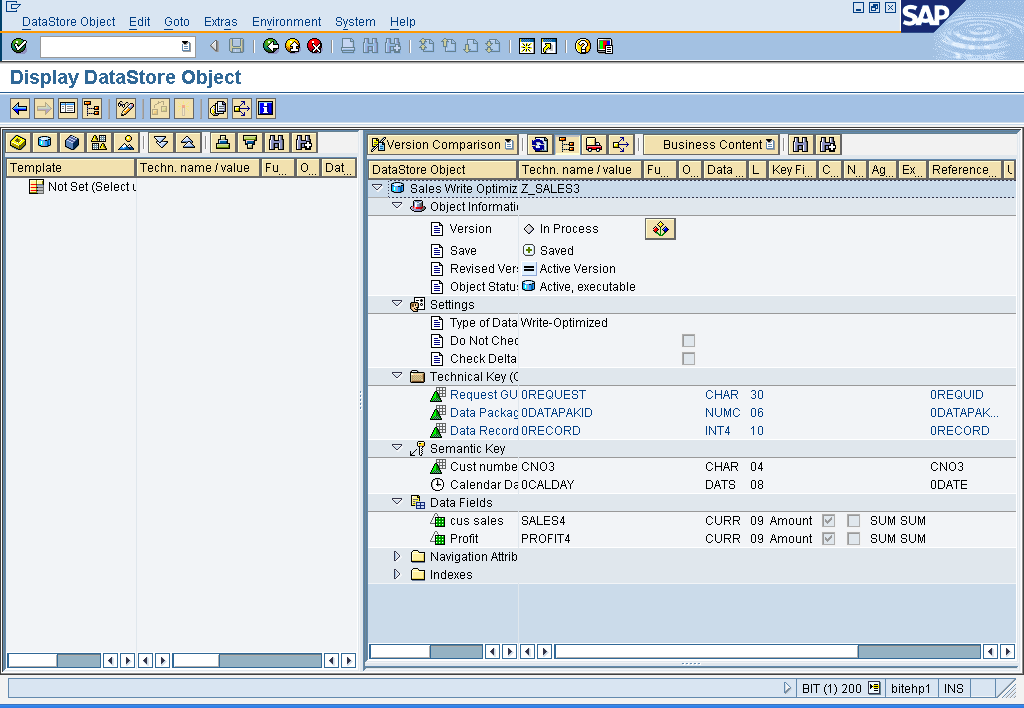
3. Load data into PSA & into write optimized DSO. Generates Error records for duplicate records, and all the duplicate records are moved to Error stack.

4. modify the records in Error stack and run the Error stack DTP.
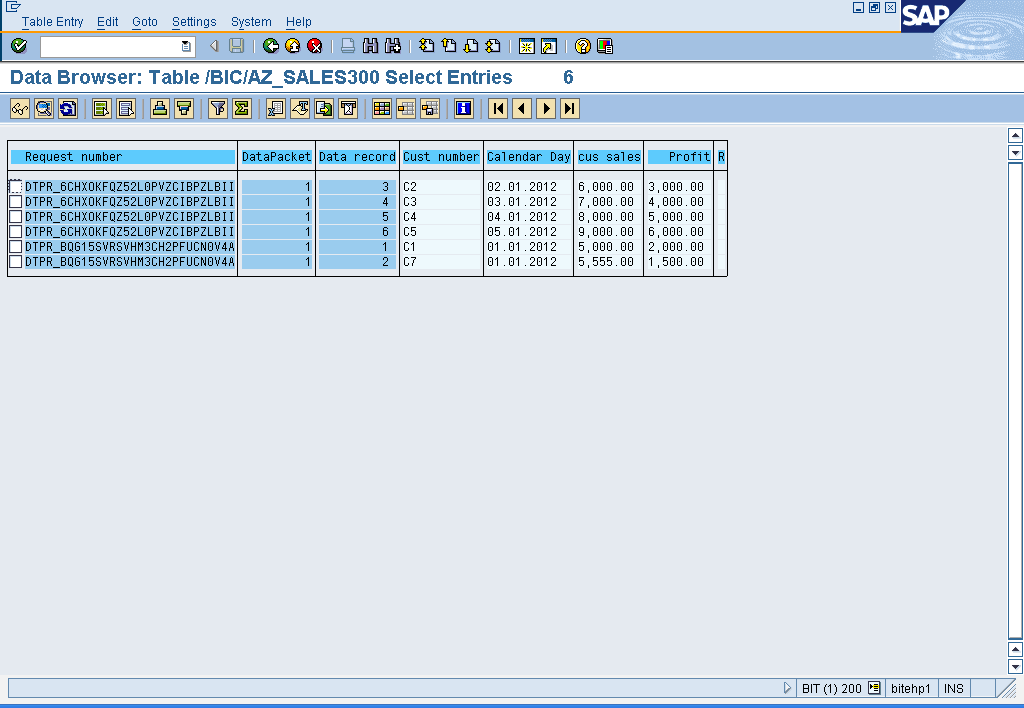
Observation:
- With the setting ‘do not check uniqueness of data’ is unchecked for the Write optimized DSO, the duplicate records with semantic key fields are treated as error records and moved into Error Stack.
Scenario 3:
Try to include data field in the Semantic keys.
Try to include data field in the Semantic keys.
- Let us try to include ‘SALES4’ data field in the semantic key fields in the Write optimized DSO.
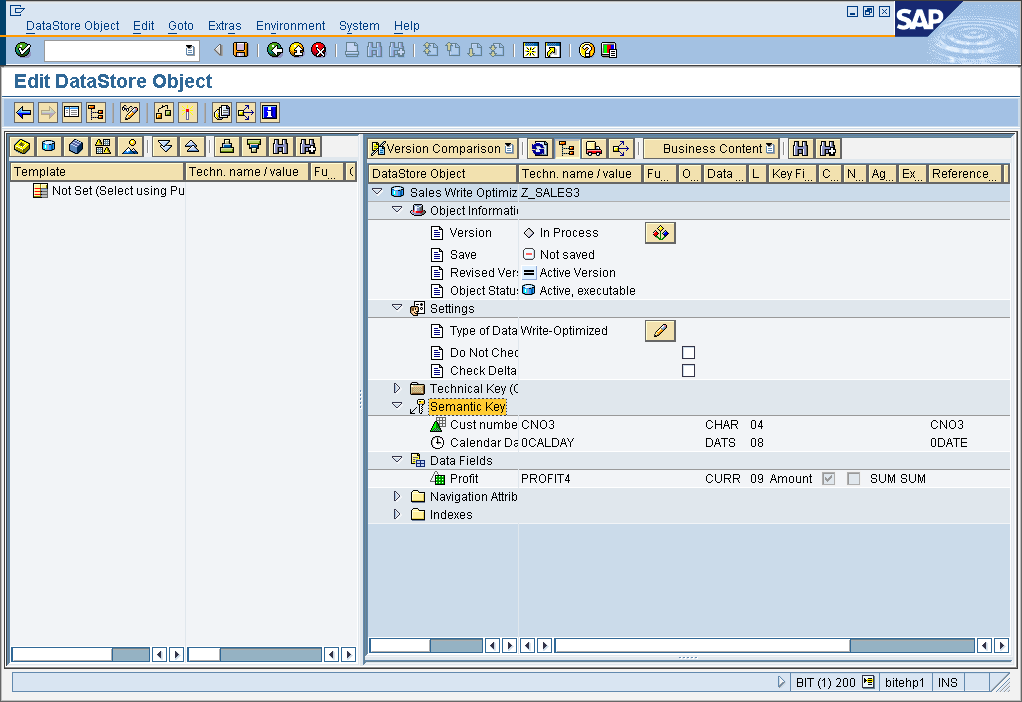
Note: it doesn’t accept a data field (key figure) to be included in the semantic key fields. We will get the following error if we try to add data field to semantic key.

Conclusion: A semantic key doesn’t contain any data fields, and a data field can never be part of semantic key.
Notes on Semantic key:
Semantic Keys can be defined as standard keys in further target Data Store. The purpose of the semantic key is to identify error in the incoming records or duplicate records. All subsequent data records with same key are written to error stack along with the incorrect data records. These are not updated to data targets; these are updated to error stack. A maximum of 16 key fields and 749 data fields are permitted. Semantic Keys protect the data quality. Semantic keys won’t appear in database level. In order to process error records or duplicate records, you must have to define Semantic group in DTP (data transfer process) that is used to define a key for evaluation. If you assume that there are no incoming duplicates or error records, there is no need to define semantic group, it’s not mandatory.
=================================================================
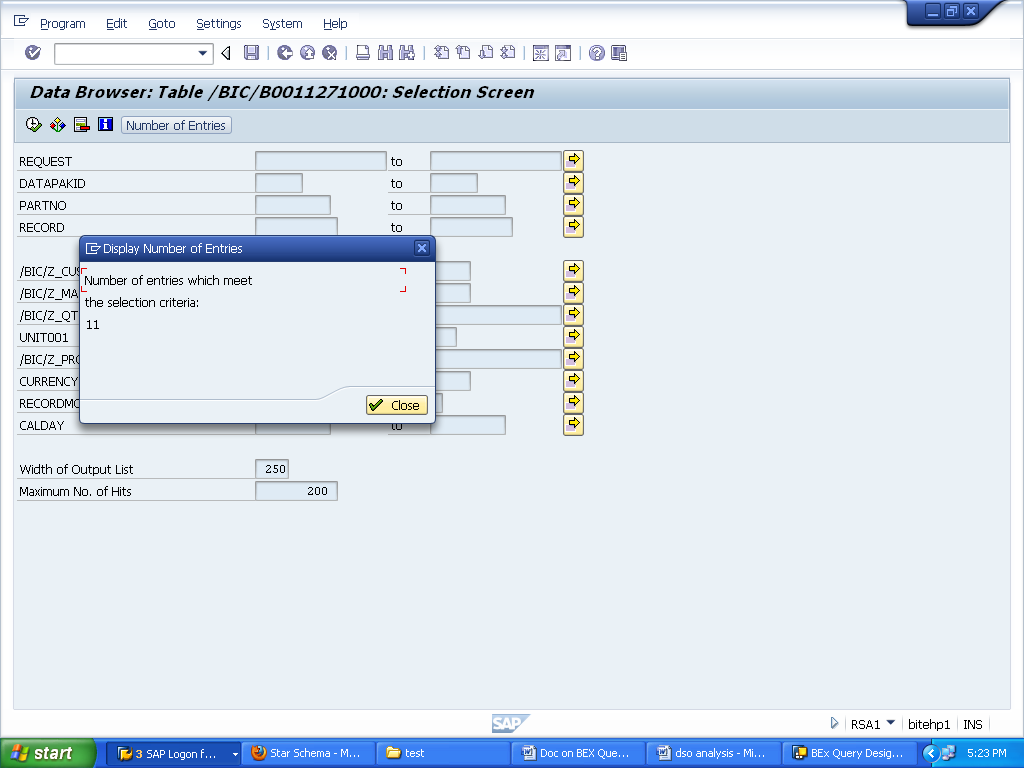
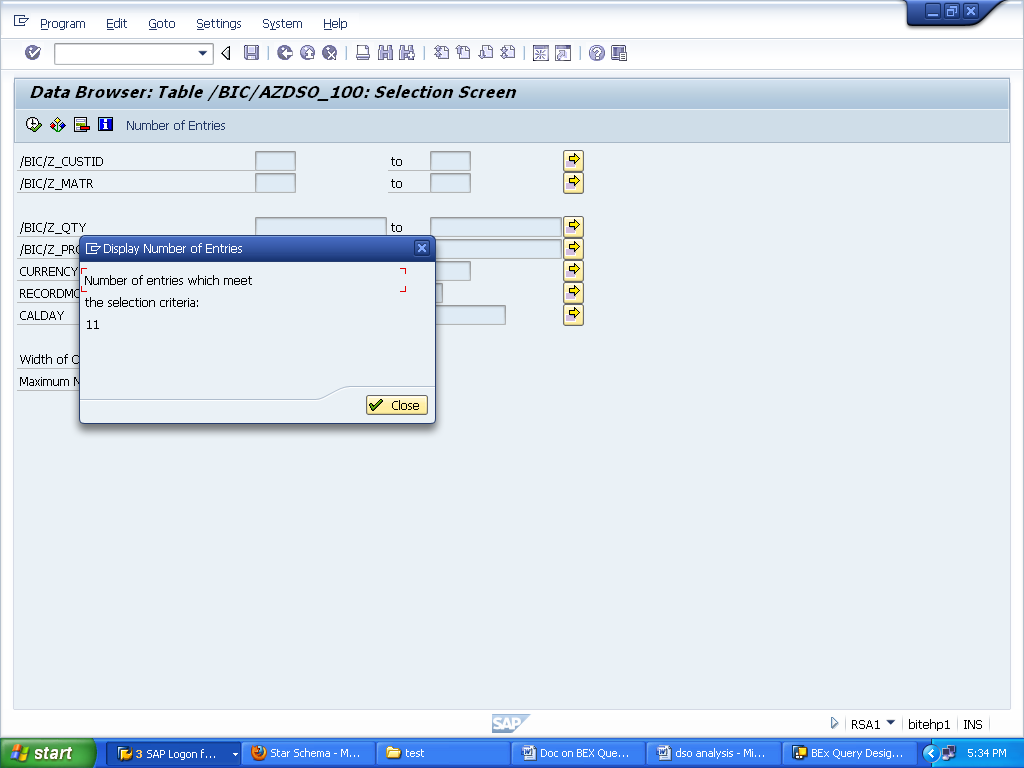
11 records has been loaded for the first load:
Records in active table :

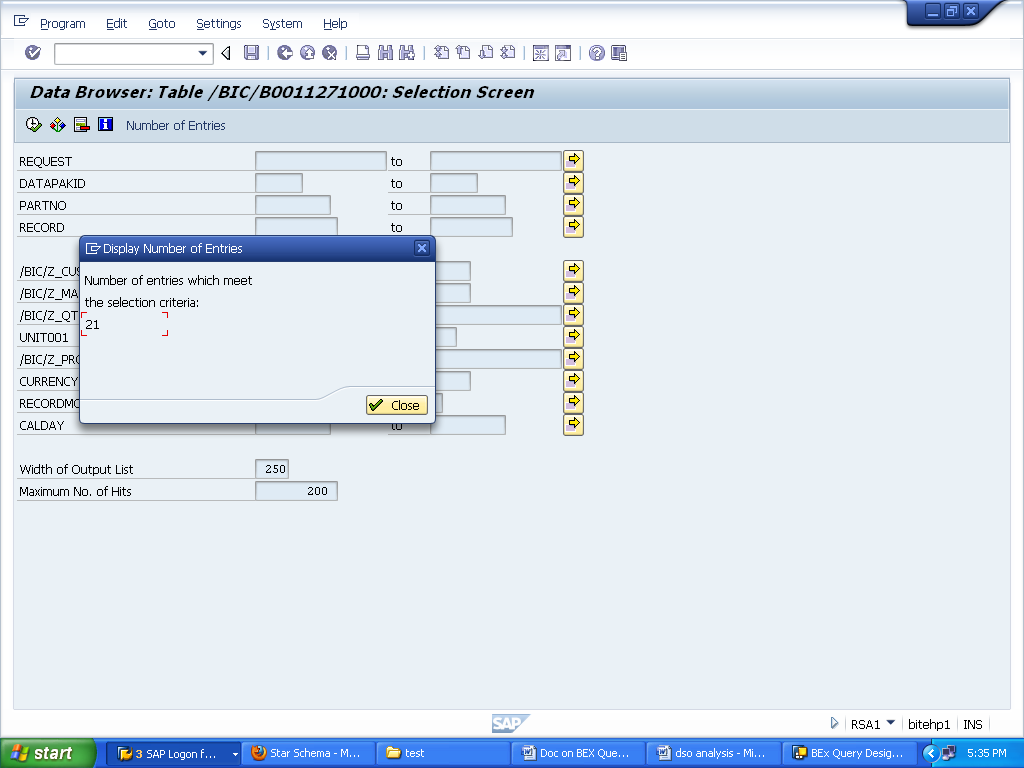
Records in Change log table :
Data in change log:

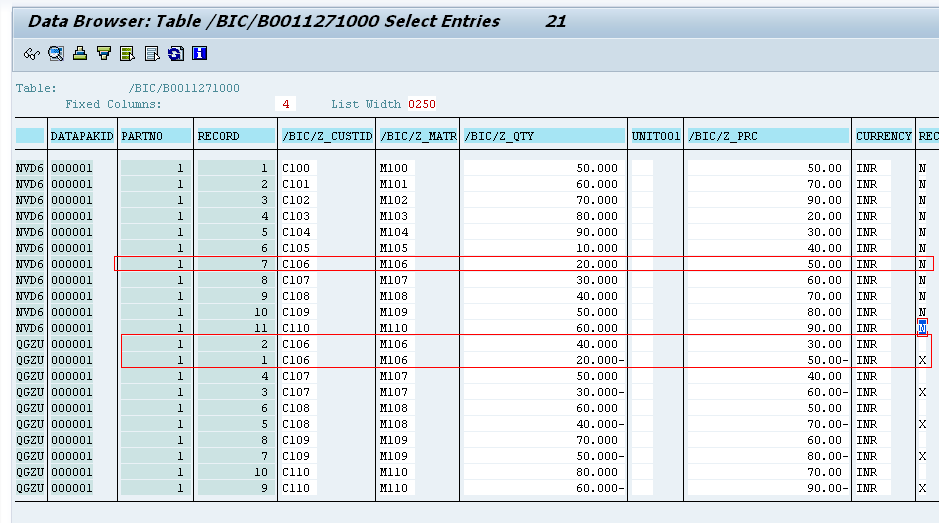
Now, 5 records had modified:
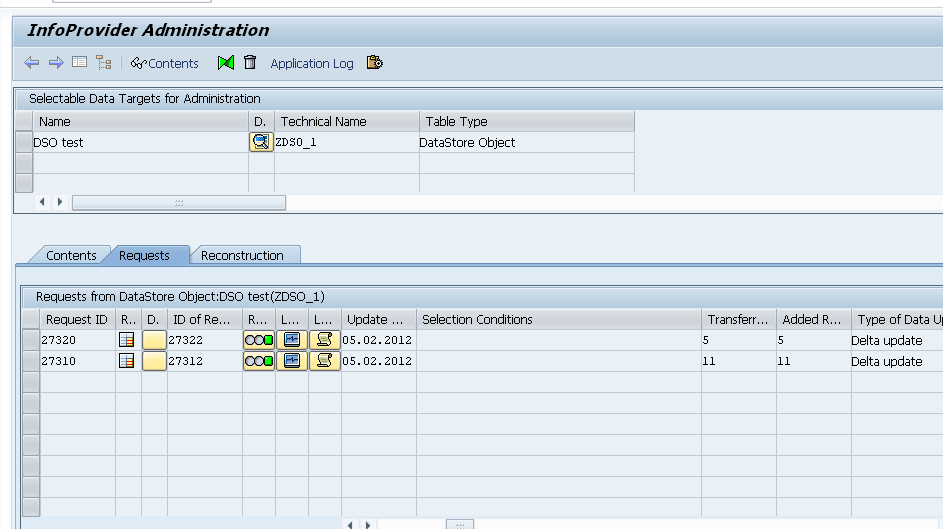
Records in Active table:
Records in Change log :
Data in change log table :
Records
|
Active table
|
Change log table
|
11
|
11
|
11
|
5 modified
|
11(With 5 modified)
|
11(new) + 5 (before) + 5 (after image)
|
Analysis:
Active table: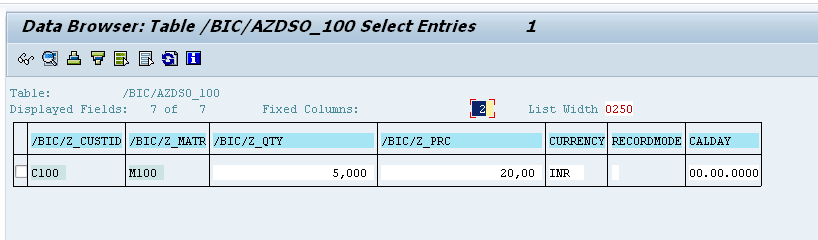
Change log table:
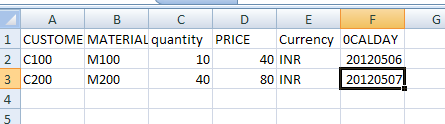
Cube:
Second request:
New data table:

Active table:
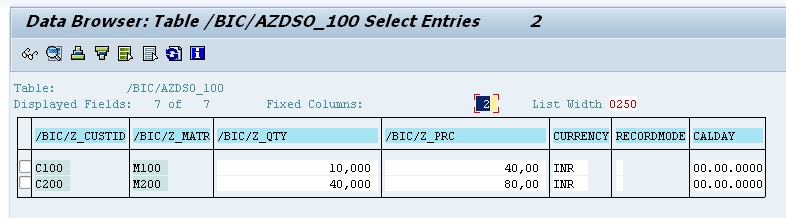
Change log table:

DSO to cube:
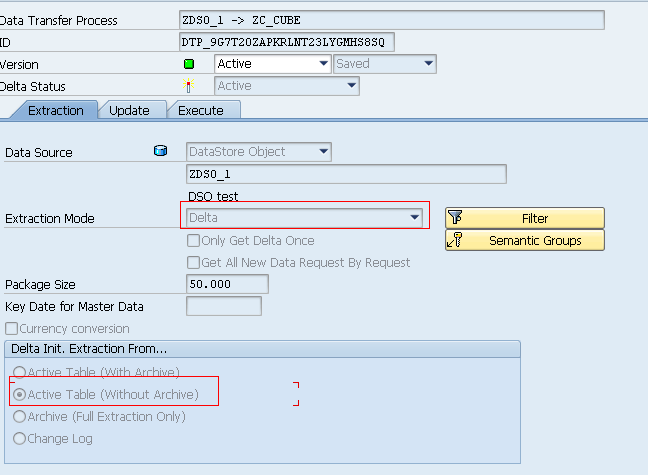

***************************************