
AGGREGATES
Aggregates are enhanced subsets of Info cubes, where the data is pre-aggregated and stored in an Info Cube structure.
Need for aggregates:
Aggregates help to accelerate response time of queries. So wherever there is a Query performance issue owing to high data read time there Aggregates will reduce the amount of data that needs to be read in the DB.
Aggregates can be created:
For Basic Info Cubes on its Characteristics, Nav. Attributes & Hierarchies.
When we need to create an Aggregate and how to analyze?
The need for the aggregate generally arises when the query performance is found to be low due to long Data read time. This can be analyzed through a simple method.
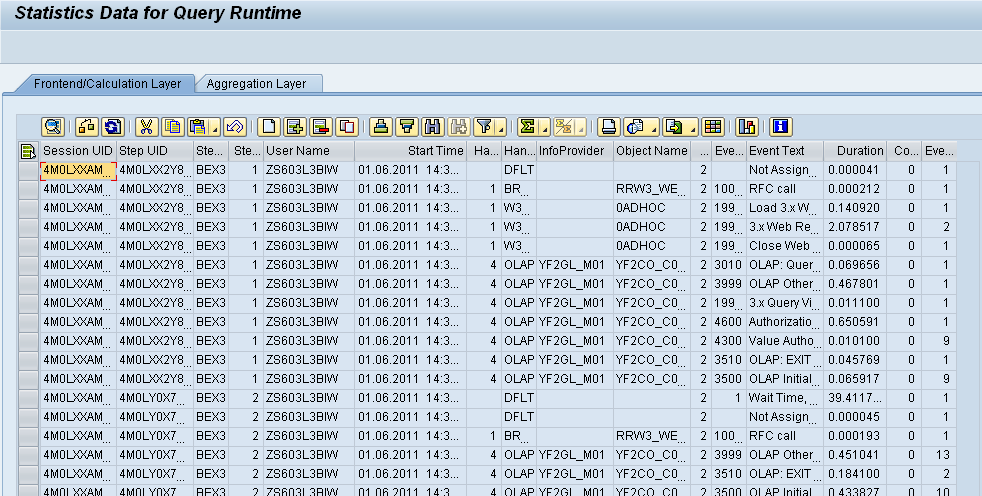
Go to RSRT and execute the query in Execute and Debug mode. Here check the statistics data option. This will provide us the Query run time statistics.
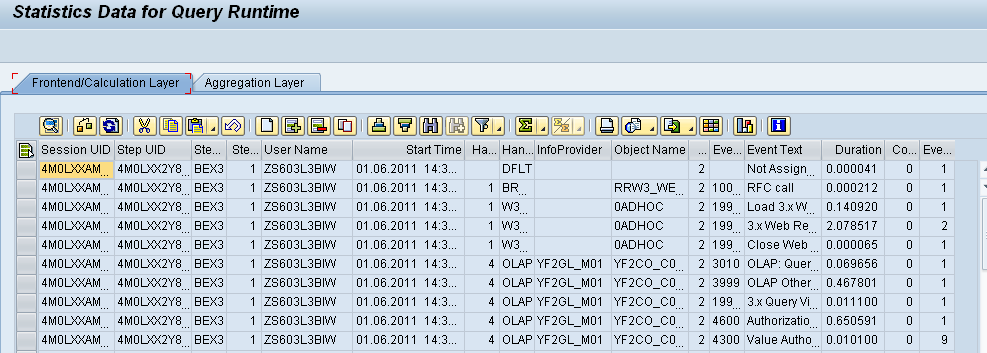
Go to Aggregation layer
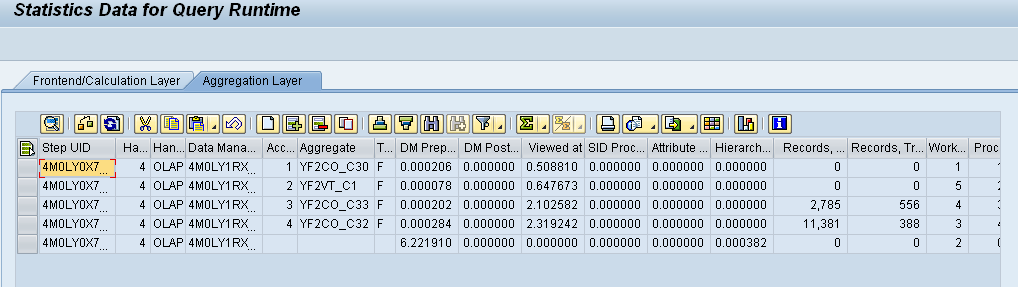
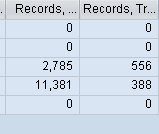
Analysis has to be done between Records
As a rule of thumb, an aggregate will be helpful if the query statistics show
Summarization Ratio > 10 Summarization Ratio > 10, i.e. 10 times more records are read than are displayed,
And also
Percentage of DB time > 30%Percentage of DB time > 30%, i.e. the time spent on database is a substantial part of the whole query runtime
This statistics can be taken from the first tab of Statics data
Right click on Cube ---- > Maintain Aggregate
Aggregates can be created in 2 ways
- Through proposal: an auto proposal evaluates the Query run time statistics on the cube and proposes the Combination of Characteristics on which the aggregates will be created.
- Through Manual process: Manually selecting the Characteristics and Nav. Attributes to create aggregates.
Good Aggregates:
Relatively small compared to parent InfoCube
Try for summarization ratios of 10 or higher
Try for summarization ratios of 10 or higher
Build on some hierarchy levels, not all
Not too specific, not too general -should serve many different query navigations
Not too specific, not too general -should serve many different query navigations
Bad Aggregates
Too many very similar aggregates
Aggregates not small enough (compared to parent cube)
Too many "for a specific query" aggregates, not enough general ones
Old aggregates, not used recently??Infrequently or unused aggregates
Aggregates not small enough (compared to parent cube)
Too many "for a specific query" aggregates, not enough general ones
Old aggregates, not used recently??Infrequently or unused aggregates
Tips to create & maintain Aggregates:
Space Constraints:
- Try to combine many queries and create less no of aggregates on Cube.
- Avoid creating aggregates with the base characteristic of the cube. For eg if Material is the base characteristic of the cube try not to create aggregate as it will occupy good amount of space.
Redundancy & Unused Aggregates:
- Avoid Duplication – Aggregates created on the Cube should be unique in combination.
- Always analyze unused aggregates and delete or Switch off aggregates to save space on the server.
Maintaining Aggregates:
SAP has provided a simple method through which Unused aggregates can be identified.On the Maintain Aggregates page details on aggregates are available to evaluate its usage.

- Valuation column evaluates each aggregate as either good or bad. The valuation starts at "+++++" for very useful, to "-----" for delete.
- Usage: If report has not used aggregate ever ( 0 ) or not used in last 2-3 months, it can be consider for deleting
- Last Update: If rollup is not happening, usually means aggregate is not part of roll up processes or has been created as back up of BIA, can be considered for deleting.
- Size of aggregate: An aggregate must be considerably smaller than its source, meaning the Info Cube or the aggregate from which it was built. If the aggregates size is larger than the source and it not used much then we can delete the same. The thumb rule here is to keep aggregates ten times smaller than its source.