
BI Accelerator
Reporting and handling of BIG DATA is one of the growing concern in the world of Data Warehousing. As the business grows the volume data also grows, as the volume of the data grows reporting takes a big hit. SAP BI Accelerator helps in reporting on huge volume of data.
What is BI Accelerator?
It is bundle of software and hardware. It has 64-Bit Xeon processor from Intel, Blade server from HP and TREX (Text Retrieval and information Extraction) search engine.
How to add a cube into BI Accelerator?
You can add cube in BI Accelerator in two ways. One go to the T- Code RSDDV

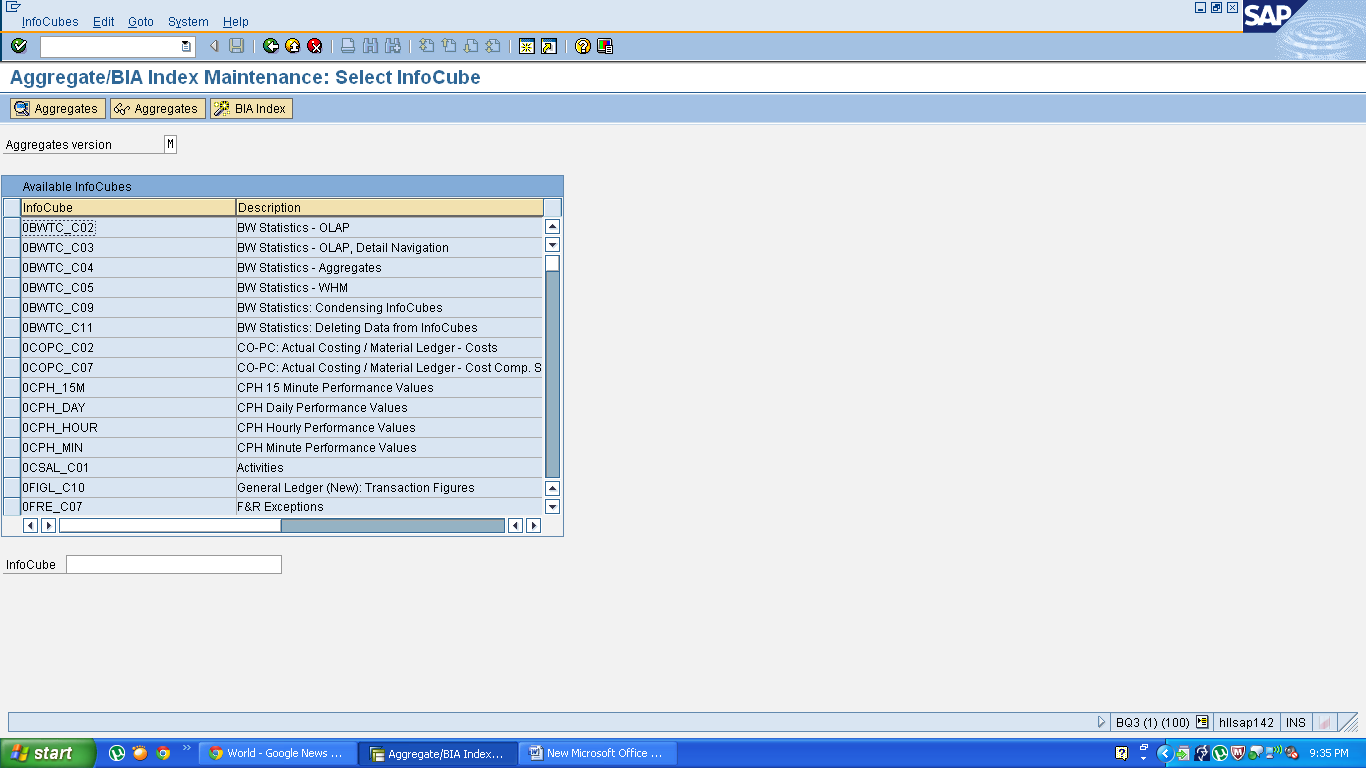
Select the cube and click on BIA Index .
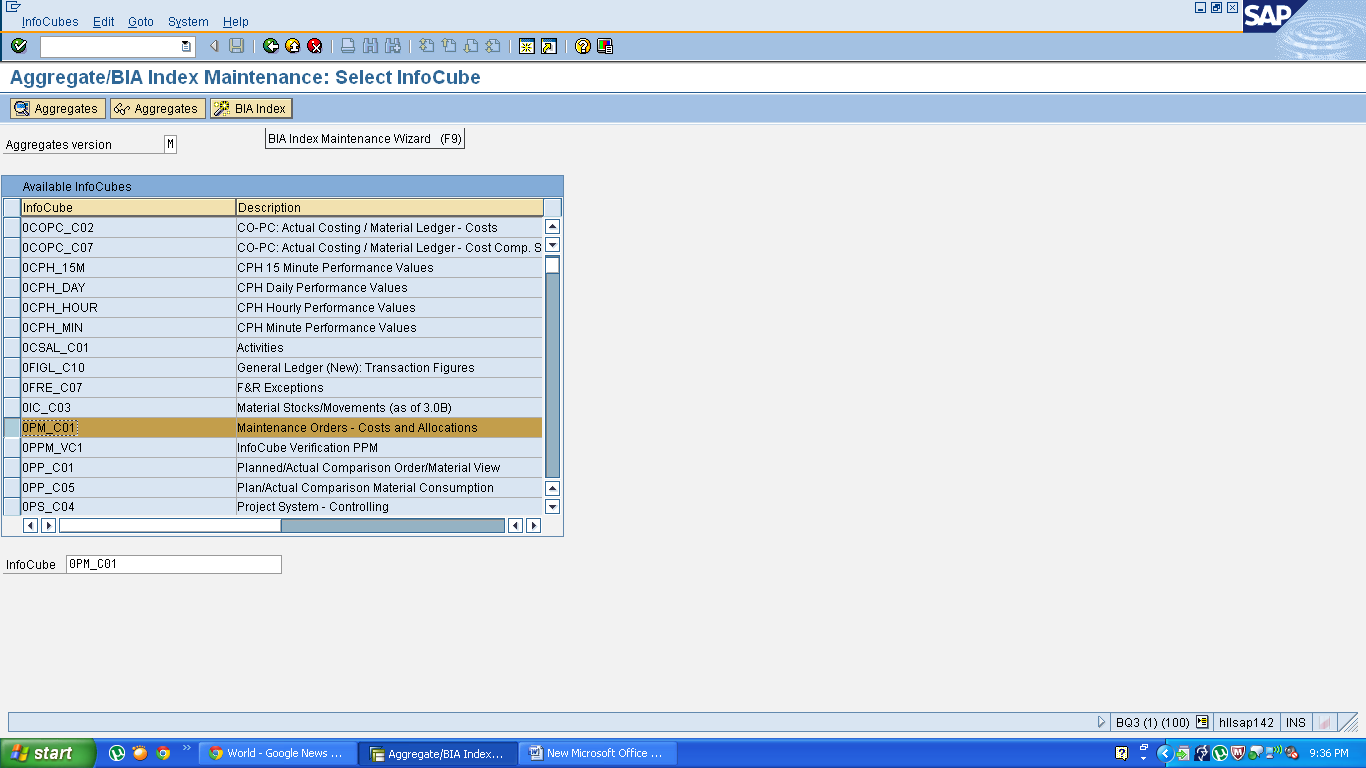
Click Continue to create index.


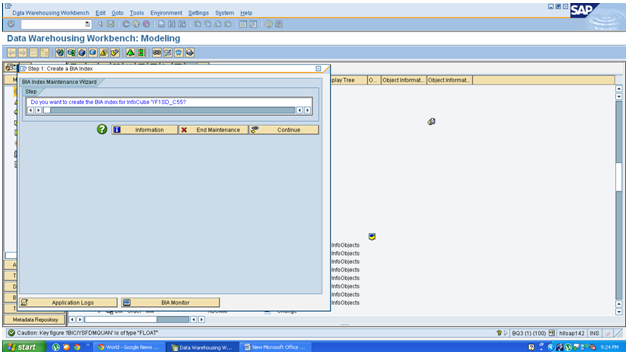

How to update the index:
For each delta / full load, roll up step need to be done. This will ensure latest data being available for reporting. The roll up step can either be done manually under Cube > Manage Tab. Or step can be added in process chain.
In process chain, there are two process steps that can be added to cube: Initial activation and filling of BIA index and Roll up filled indexes.

Note: In the earlier version of BIA only the Cubes can be added in the BIA. In the latest’s version DSO also can be added in BIA.
How does BI Accelerator work?

- Creating new indexes can be time consuming. The build time depends on:
- The size of the records (length)
- The number of records
- The number of SAP BW Accelerator processors
- The network transfer speed between Business Warehouse and BI Accelerator.
Three step process in index creation of Info cube.
- Master data is processed Y, S and X tables. Y – Time dependent SID table for attributes, S – SID tables for attributes and X – Time independent SID tables attributes.
- The fact tables grouped and indexed. This occurs by merging the E and F tables into one F table prior to indexing it. This is done automatically and does not change the basic cube.
- The dimension tables are indexed. This include all D-tables (Max 16)
The process of indexing starts with a database lock on each table. The next step is a data transfer to a temporary BI Accelerator file and transferring the data to BIA. The final step is to write the indexes to memory and activate it for queries. (See the above Figure)
Increasing Index Creation Performance:
- To increase index creation performance, you can change the global parameters in BWA. You can change the parameters in T-CODE RSRV
- Pay particularly attention to the number of parallel processes available (max 10 per available physical processors)
- Make sure the memory buffers are set large enough to accommodate large info cubes.
- Review consistency check is recommended.
- How does the blade server stores the info cube data in BI Accelerator
Cube Dimensions are evenly stored on individual blades.
Fact table is horizontally partitioned and stored across all blades, whereby columns can be accessed individually (vertical decomposition).
TREX Architecture 

Blade server (1) Blade server (2) … .Bladeserver (n).
TREX Architecture:
Name Server:
It holds data about the central components of a TREX system (TREX servers, indexes, and queues). Load-balancing, the name server accepts requests and distributes them to the responsible TREX servers. It is responsible for distributing indexes and search queries and Ensuring high availability .The name server launches several watch dogs. They constantly monitor whether the TREX servers are available. If a TREX is not available, the name server ensures that the TREX server that is down does not receive any requests.
Queue Server or Alert Server:
It coordinates the processing steps that take place during indexing. It collects incoming document, triggers preprocessing by the pre processor, and further processing by the index server. In addition, the queue server can trigger index replication and integration of the delta index in the main index.
RFC Server:
It is responsible for the communication between an SAP system and the TREX servers
Index server:
The index server indexes and classifies documents and answers search queries. The processing takes place in the engines that belong to the index server. It has Search engine, Text-mining engine and Attribute engine.
Administration of BI Accelerator:
T -Code : RSDDBIAMON or RSDDBWAMON
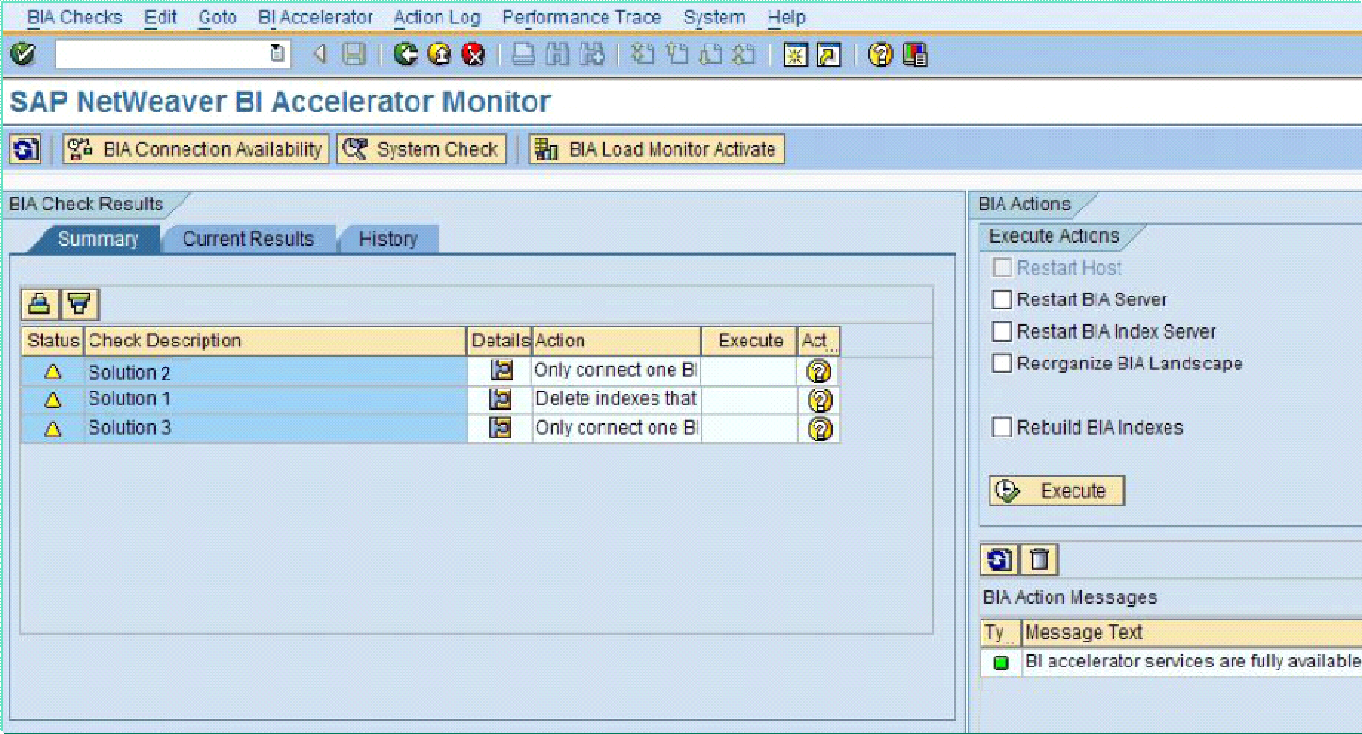
Check if BW is still connected physically to the BW system
System Check
Checks if the blades and file system is operating normally
Load Monitoring
Keep track of performance of the load process (read, writes, compression and time spent).
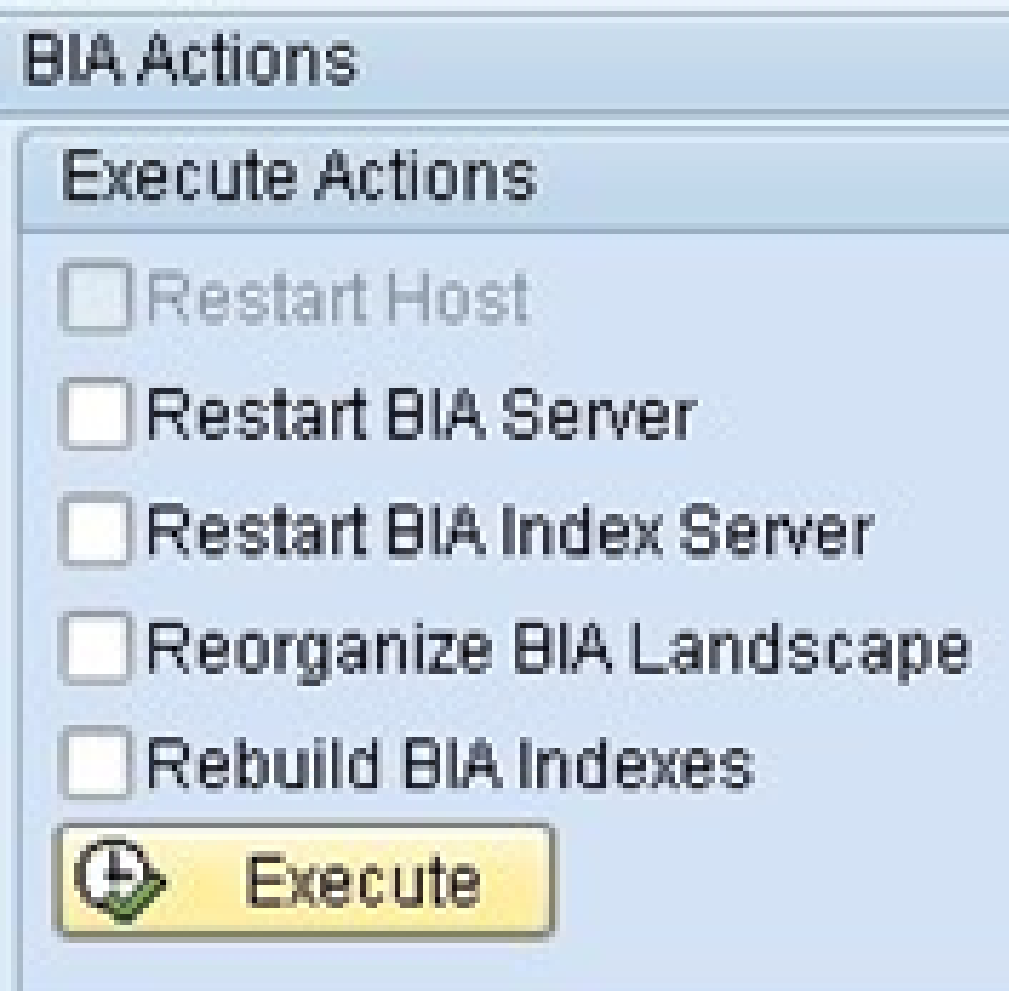
Restart BIA server: It restarts all the BI accelerator servers and services.
Restart BIA Index Server: This restart the index server.
Reorganize BIA Landscape: If the BI accelerator server landscape is unevenly distributed, redistributes the loaded indexes on the BI accelerator servers.
Rebuild BIA Indexes: If a check discovers inconsistencies in the indexes, delete and rebuild the BI accelerator indexes.
You can turn off the BWA index query availability for Info cubes through the transaction “RSDDBIAMON2”

Limitation of BI Accelerator:
There are still some limitations. For example you cannot use the exception aggregation for single key figures in BWA if it uses:
- Virtual key figures
- Conversion before aggregation
- Formula calculation before aggregation
- Non-cumulative key figures