
Introduction to Database:
The main purpose of database is to store data and this data can be used for later purpose (analysis). Any big Enterprise we consider, they always store their business data into database. So that they use this data for analyzing their business.
Any database like (Oracle , Ms Access, SQL Server, Sybase ……) always store data in form of a structure called “TABLE”.
Table: Table is set of ROWS and COLUMNS
Each Row in a table is referred as Record
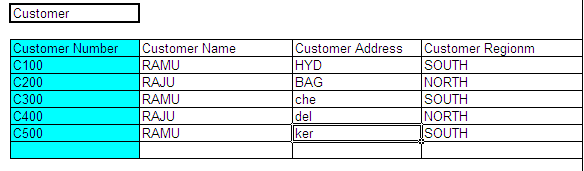
Primary Key:
It is a column in a database table which can maintain uniqueness for all the records in the table. It can be used to uniquely identify each and every record in the table
In above example: In the Customer Table the “Customer Number” is the Primary Key.
Every table must have a Primary Key (In Exceptional Cases we can have a table without a primary)
we have 2 types of columns in a table.
1) Key Column
2) Non - Key Column
Key Column:- Column which is a part of Primary Key.
Non - Key Column:- Column which is not a part of Primary Key.
All Non - Key Columns act as Attributes or Properties for Key Column.
Composite Key:-
When 2 or more columns act as the primary key in a table.
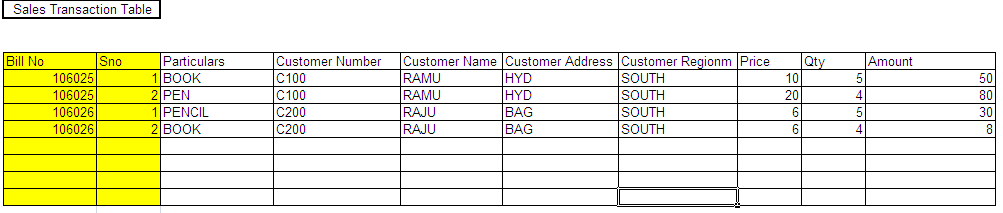
In above Example, Bill No & Sno together act as the primary key in the database table, So this is referred as Composite Key.
It is the limitation of the database that we can only have a maximum of 16 columns act as the composite key.
De-Normalized Table:
When we store all the data in a single big table, and we find the data being stored redundently/Duplicatly,we call it as De-Normalized Table.
Limitations of De-Normalized Table:
1) Wasting Database Space
2) Complexity will be high.
Normalized Table:
Instead of storing the data in a single table, we split the data into multiple smaller tables connected with Primary key - Foreign Key where there is no data redundency - Normalized tables.
Normalization:
The process of converting De-normalized tables into normalized tables by using normalization forms.
Foreign Key:
When a Primary key of one table takes part in the other table we call it as Foreign Key.

Software Engineering process:
Whenever we develop a software we follow the SDLC cycle . SDLC contains 5 steps:
- Requirement Gathering
- Design
- Develop
- Testing
- Deploy
- Maintenance & Support
Requirement Gathering:
At this phase we gather the requirements from the end users and understand the business process.
Design:
As we know every application will have the Front End (Interface Screens) & Back end (Database). As part of this phase we will have to design the Front end screens and Design the Database (Database design is referred in the Next Section)
Develop
At this phase by using some Programming Language & some database we develop the software.
Testing
At this phase we test the software, weather the software is working as per the user requirements or not.
Deploy
Once the Software is tested perfectly we deploy the software at the client location. So that the business can start using the software.
Maintenance & Support:
Once the software is deployed, we will have to provide the Maintenance & Support for any issues what the client/ Business faces.
Applications & Types:
Any application will have 4 aspects:
- PL + database + OS + Concept
- Programming Language is used to design the frontend (i.e, Interface screens &Application logic)
- Database is used to design the backend to store data
- Operating system to run the application
- Concept is the reason for what the application is designed for
We have 2 types of applications:
- OLTP
- OLAP
OLTP [Online Transaction Process]:
OLTP applications are mainly to record all the transactions of the business
OLAP[Online Analytical Processing]:
OLAP application takes in all the transaction data from different OLTP applications and provide the reports for analysis.
Database design:
Database Design in OLTP:
- ER Model [Entity Relationship Model] is used to design the database for OLTP applications.
- Database designed with ER Model is 2 Dimensional & it is completely normalized.
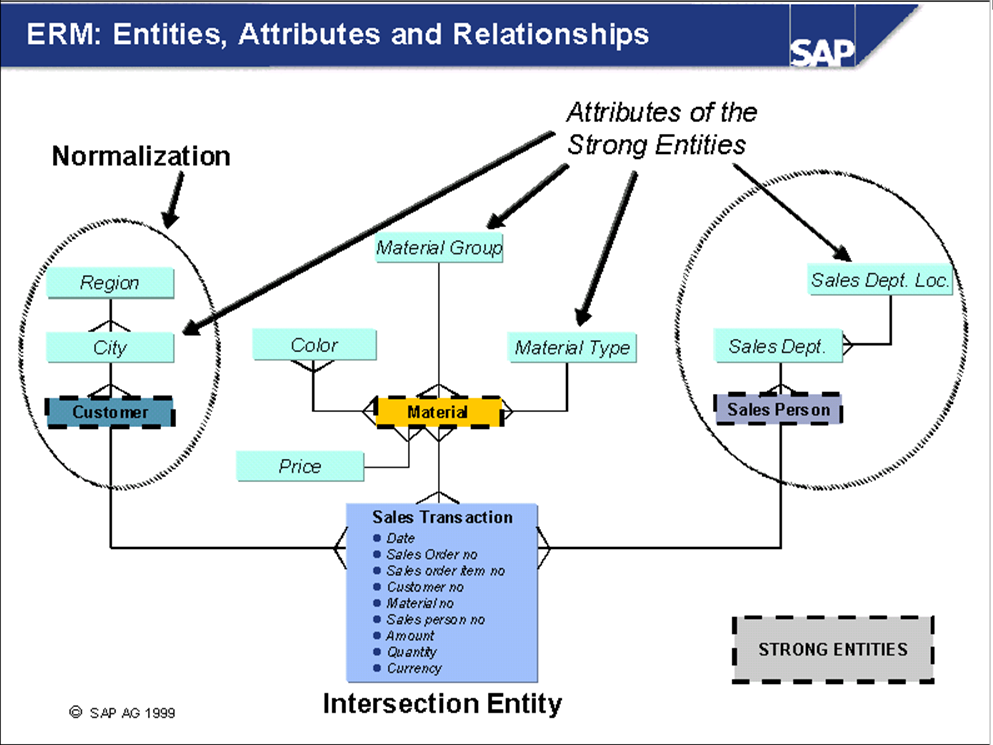
Database design in OLAP:
In OLAP applications we store data in MDM[Multi Dimensional Format] by using the following models:
- Start Schema or Traditional Star schema
- Extended Start schema or BW Star schema or BI star schema
- Snow Flake
- Hybrid
Star Schema:

- Star schema is an MDM ( Multi Dimensional Model ) which contains Fact table / Transaction data Table at the center, surrounded by Dimension tables / Master Data Tables existing within the Cube.
- These Dimension Tables / Master Data Tables are linked to the Fact table / Transaction data table with Primary Key – Foreign Key Relationship.
Difference between ER Model & Star Schema
ER Model
|
Star Schema
|
2 Dimensional
|
Multi Dimensional
|
Normalized
|
De-Normalized
|
Limitations or Dis-advantages of Star Schema:
- Master Data is not Reused:
In Case of star schema, Master data is stored inside the cube. So Master data cannot be reused in other cubes.
- Degraded performance:
Since all the tables inside the cube contains Alpha-numeric data, it degrades query performance. Because processing of numeric’s is much faster than processing of Alpha-numeric’s
- Limited Analysis:
In case of Star schema, we are limited to only 16 dimensions.
Extended Star Schema:
In case of extended star schema, we will have Fact table connected to the Dimension table and the Dimension table is connected to the SID table and SID table is connected to the master data tables.
Fact Table and Dimension table will be inside the cube.
SID table and Master data tables are outside the cube

One Fact table can get connected to 16 Dimension tables, one Dimension table can be assigned with maximum of 248 SID tables (248 characteristics).
Master data & SID tables:
Every characteristic Info Object will have its own SID table to convert the Alpha-Numeric value to a Numeric value. But the Key figure Info Object will not SID table because the keyfigure value is a numeric.

When ever we insert a value into the characteristic Info Object, system will generate an SID number in the SID table which is a numeric value
Each Characteristic can have its own master data tables (ATTR,TEXT,HIER)
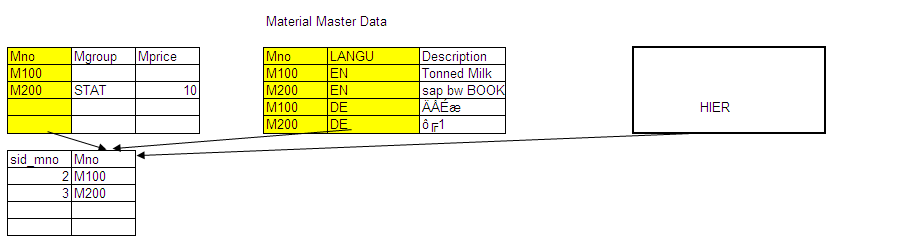
Attribute Table is used to store all the attribute or properties data
Text table is used to store the description in multiple languages
Hier table is used to store the Parent-Child data.
As you can observe the in above picture, Material Attribute table holds all the attribute information like (Material Group, Material Price), Material Text table Holds Description in multiple languages.
So when we load master data, SID’s are generated in the SID table.
Fact Table & Dimension Tables:
Fact Table:
- Fact Table will have Dimension ID’s and Key figures.
- Maximum DIM ID’s – 16
- Maximum Keyfigure – 233
- The Dimension ID’s in the Fact table is connected to the Dimension Table.
- Fact Table must have at least one Dimension ID.
Dimension Table:
- Dimension Table contains Dimension ID and SID columns.
- One column is used for Dimension ID
- We have maximum of 248 SID Columns
- We can assign maximum of 248 characteristics to one dimension.
When we load Transaction data into Info Cube, System generates DIM ID based on the SID’s and uses the Dim ID’s in the Fact Table.
We can load the Transaction data without master data, In this case system first inserts the Master data into Master data tables, then generates the SID ID’s and based on these SID ID’d it generates DIM ID’s and uses the DIM ID in the fact table.
Standards to Design Info Cube:
- If we have 2 characteristics which are related as 1:1 or 1:M, we should assign them to same Dimension table
- If we have 2 characteristics which are related as M:M, we should assign them to different Dimension tables
- Modeling of Characteristics:
- If we model the Characteristic as an attribute of another Characteristic, It gives Present truth because the property of master data is overwrite.
- If we model the Characteristic as a separate Characteristic and assign the Characteristic to an Dimension table, It gives Fact.
- Modeling of Keyfigures:
- If we Model the Keyfigure as an attribute of another Characteristic, It gives present truth because the property of master data is overwrite.
- If we model the keyfigure inside the Fact table, it gives fact because the property of Info cube is additive.
SAP BW Architecture:
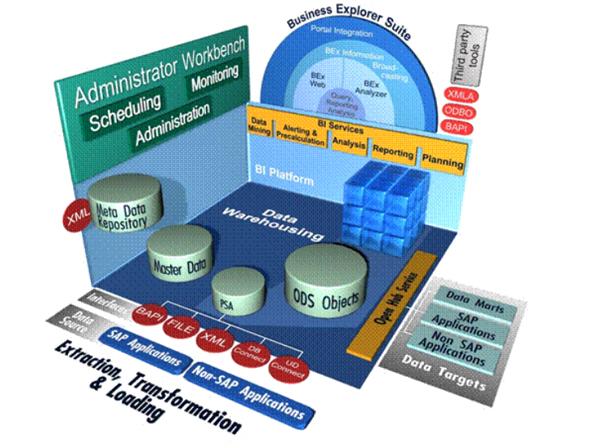
Points to be Noted regarding SAP BW:
- In SAP BW we work with objects like (Info Cube, ODS, Info Source, data Source, Info Package, Update Rules, Transfer rules, BEx queries…….)
- In SAP BW we will have 2 types of Objects:
- Standard or Business Content Objects:
- These are the readymade Objects delivered by SAP.
- All the standarad objects will have their technical name starting with the number 0.
- All Business content objects will be in delivered version.
- Customized Objects:
- These are the objects what we create as per our requirements.
- Every Object in SAP BW will have the Technical name and Description
- Once the Object is created we cannot change the technical name but we can change the description
Info Area:
Info Area is like “Folder” in Windows.
It is used to organize the objects in SAP BW.
Info Object Catalogs:
Similar to Info Area, Info Object catalog is used to organize the Info Objects based on their type.
So we will have Info objects catalogs of type Characteristics & Key figures.
Info Objects:
It is the Basic unit or object in SAP BW used to create any structures in SAP BW(Info Cube, ODS, Info Source…..)
Each field in the source system is referred as Info Object in SAP BW.
We have 5 types of Info Objects:
- Characteristic
All Business subjects what we analyze
Ex:- Customer Number, Material Group, Company Code, Employee Group
- Key figure
All Quantitative measures used to analyze the subjects
Ex:-Price, Revenue, Qty, Number of employees, VAT %
- Time Characteristic
Characteristics which maintain Time factor information
We cannot create the Time Characteristics
Ex:- 0CALDAY, 0CALMONTH,0CALYEAR …
- Unit Characteristic
Characteristics which can be used to hold Currencies and units.
Like 0CURRENCY, OUNIT
We always have to create unit Characteristic by taking 0CURRENCY OR 0UNIT as the reference.
- Technical Characteristic
Characteristics which hold technical details like Request number, datapacket no, Record Number.
Ex:- 0REQUID….
Info Cubes:
- Info Cube is an Multi-Dimensional Object which is used to store the transaction data.
- Info Cube contains Fact Table & Dimension Table
- Info Cube is referred as datatarget because it holds the data physically in it.
- Info cube is referred as Info Provider because we can do reporting on Info cube
- The property of Info Cube is additive.
ODS:
- ODS stands for Operational data Store
- It is an 2 Dimensional object
- The property of ODS is overwrite
- We use ODS for staging the data and also detailed reporting
Info Source:
- Info Source defines communication structure
- Communication structure is a group of Info objects which are required to communicate the fields coming from the source system
- We have 2 types of Info Sources:
Direct update
- Direct Update Info Source is used to load the master data objects
Flexible Update
- Flexible update is used to load the transcation data to any data targets like(Info Cube, ODS)
Data Source:
- Data Source defines Transfer Structure
- Transfer Structure indicates what fields and in what sequence are they being transferred from the source sytem
- We have 4 types of datasource:
- Attr: used to load master data attr
- Text: Used to load text data
- Hier: used to load hierarchy data
- Transcation data: used tgo load transaction data to Info cube or ODS
Source System:
Source system is an application from where SAP BW extracts the data.
Transfer Rules & Update Rules:
UR & TR are used to perform all kind of transformations to the data coming into SAP BW.
Source system Connection
We use Source system connection to connect different OLTP applications to SAP BW.
We have different adapters / connectors available:
- SAP Connection Manual
- SAP Connection Automatic
Both these connections are used to connect any SAP application to SAP BW by RFC connections.
Ex:- we use this connection to connect SAP R/3, SAP APO,SAP CRM to SAP BW
- My Self Connection:
We use this connector to connect SAP BW to the Same SAP BW server.
We generally use this to load data from one Info Cube to another Info Cube.
- Falt file Interface:
We use this adaptor to load data from flat files (It only supports ASCII or CSV files)
- DB connect
We use this connector to connect any SAP certified database to SAP BW.(Certfied databases like Oracle, SQL Server, DB2…)
- External Systems with BAPI
We use this connector to connect any 3rd party ETL tools like Informatics or Data Stage.
Info Package:
- Info package is used to schedule the loading process.
- Info package is specific to data source
- All properties what we see in the info package depends on the properties of the DataSouce.
Business Explorer[BEx]:
We use BEx components to design all the reports in SAP BW.
RSA1: [Administrator workbench]:
- Modeling
- We create the BW objects like (Info Area, Info Objects, Info Cube, Info Source, ODS, Multi Provider, Info Set)
- We do perform procedures to load data into these objects.
- Monitoring
- We monitor all the BW Objects
- we do even monitor the Loading Process
- Reporting Agent
- To run / schedule the BEx reports in the background.
- Transport Connection
- We use tab to transport the objects from one BW server to another
- Documents
- BDS(Business Document Services), used to maintain documents within SAP BW
- Business Content
- All the BC objects will be in Delivered version, But if we need to use the objects they sholud be available in Active version, So in the Business Content Tab - we install the Business content objects ( Creating a Copy of the Deliverd version objects into Active Version)
- Translation:
- We use this tab to translate the objects from one Language to another Language
- When we translate an object only Description of an Object will change but not the Technical Name
- Meta Data:
- Meta data is nothing but data about Data
- Meta Data is Maintained in Meta Data Repository maintained by Meta Data Manager
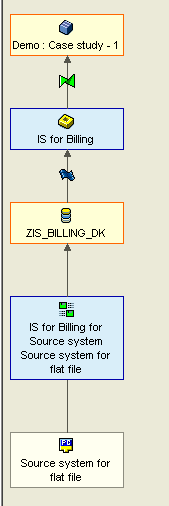
How to load data from Flat file to Info Cube:
Case Study – 1
Refer to Recording file – “How to load data from Flat file to Info Cube.wrf”
Pre-requistes:
Source System connection Between Flat file and SAP BW.
Steps:
1) Design the Info Cube.
2) Implement the Design in SAP BW
2.1) Create the Info Area
2.2) Create the Info Object Catalogs
2.3) Create the Info Objects
2.4) Create the Info Cube
2.5) Loading the Info Cube from Flat file.
2.5.1) Created the Application Component
2.5.2) Create the Info Source
2.5.3) Assign the Data Source to Info Source
2.5.4) Activate the Transfer rules
2.5.5) Create the Update Rules
2.5.6) Create the Info Package and schedule the load
|  |
Deleting Data in Info Cube:
- Deleting data based on the request
- Delete Data
- Selective deletion
ETL Process:
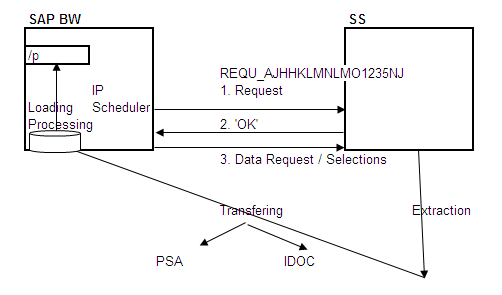
When we start the Infopackage SAP BW triggers the loading process with the below steps:
- SAP BW sends a request to the source system
- It gets confirmation “OK” from the source system
- Then SAP BW send the data request
- Based on the Data Selections, the data is extraction from the source system
- The same data is transferred to SAP BW (Transfer methods PSA & IDOC)
- Then the data is loaded into the Data target through Transfer rules & update rules.
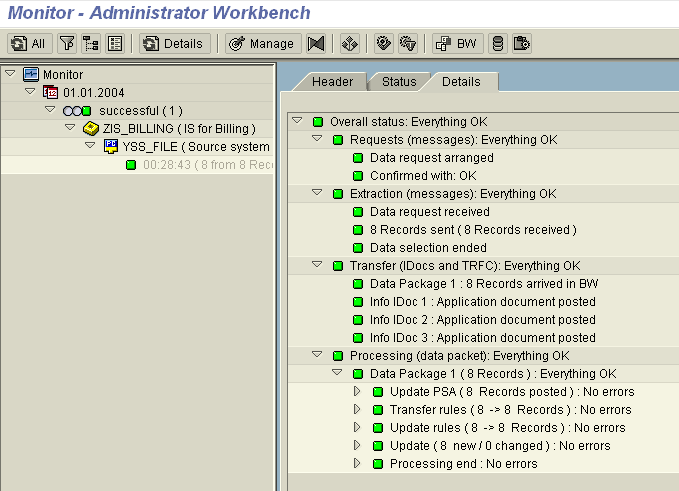
Transfer Methods [PSA & IDOC]:
PSA:
- Presistant Staging Area
- It is a 2 Dimensional Table.
- Data is transferred directly to PSA table and Information is transferred through Info IDoc’s
- When we activate the transfer rule with PSA as the Transfer method, the system will automatically create the PSA table.
- Every Data Source will have its own PSA table.
- We can find the PSA table of a Data Source by using the T-code SE11
- Structure of the PSA Table:- Transfer structure + 4 technical fields (Request No, Data packet ID, Record No, Partition No).
- PSA holds Replica of data coming from Source.
- We can do editing in PSA
- Error handling is possible with PSA
- We can reload the records from PSA to the Data target by using - Reconstruction
- We can delete data in PSA (Generally we delete data in PSA which is older than 7 days)
- Allowing Special Characters into SAP BW - RSKC [76].
- RSALLOWEDCHAR
IDOC:
- Intermediate Document
- It is the Standard used to transfer the data in SAP environment.
- Data is transferred through Data Idoc's and Information is transferred through Info IDoc's.
- IDoc Maintenance
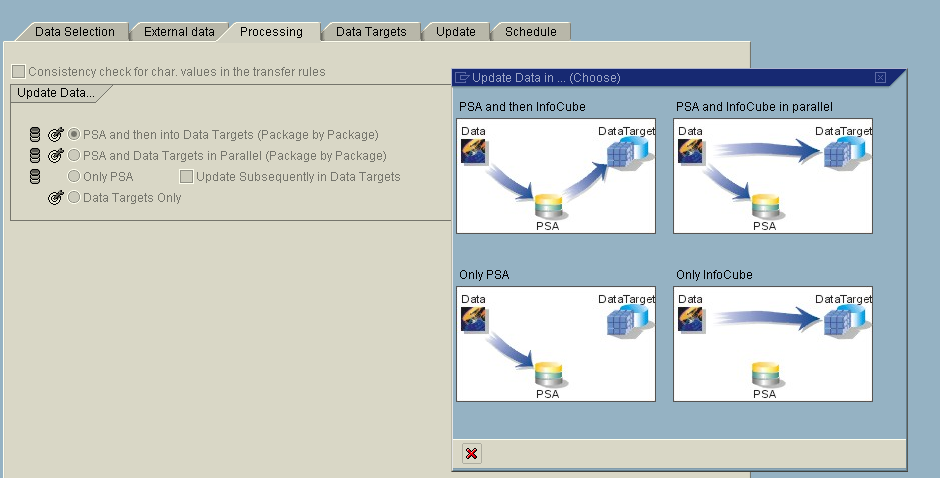
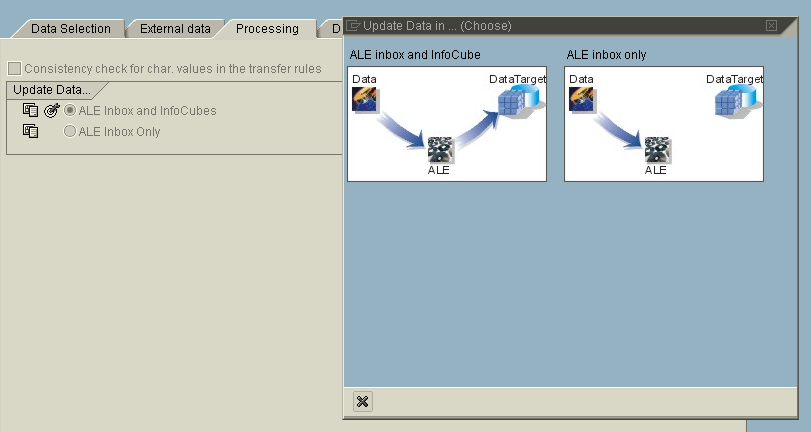
Processing Types
Processing types differ based on the Transfer methods.
PSA:
IDOC:
Error Handling with PSA:
Refer to the Document – “Error handling with PSA.wrf”
How to control the Datapacket size for a particular DataSource:
Refer to Document – “Control Data Packet size.wrf”
How to Extract data Selectively?
Refer to the Document – “Selective Loading (Data Selections).wrf”
How to write a routine in the Data Selection Tab of the Info Package (Dynamic Data Selections)?
Refer to the Document – “Dynamic data Selections.wrf”
Infopackage Update Modes:
Full Update:
It extracts all the records from the Source system with respective to data Selections.
Initialize Delta Update:
It is similar to Full update but enables us to run the Delta updates once the init is successful
Delta Update:
It only extracts the data what is newly created or modified since the last update.
Note:-
- With whatever data selections we run the init update, delta update also should run with the same data selection
- In the Infopackage we can see the Delta update option only if the data source supports delta.
Transfer Rules:
By using transfer rules, we can do mapping between Transfer structure & communication structure.
Types of transfer rules:
- Direct Mapping: We use option to map the value from a source field in the Transfer structure to the target Info object in the communication structure.
- Constant: We use option to specify a fixed/constant value for the records loaded through transfer rules.
- Formula: we use option to implement a formula by using Formula editor.
- Routine [Transfer Routine]: when use this option to transform the data by using ABAP/4 code. When implementing a transfer routine we must refer to the fields by using the structure name as “TRAN_STRUCTURE” i.e, [TRAN_STRUCTURE-/BIC/PRICE]. When debugging the name of the transfer routine will be formed as COMPUTE_FIELDNAME.
Refer to the Document – “Transfer rules_1.wrf”
How to debug Transfer routine?
Refer to the Document – “Debug transfer Routine.wrf”
Refer to the document – “Tranfer routine (If condition).wrf”
Update Rules:
Update rules specify the mapping between Source object and Target object. We use update rules to perform all kind of Transformations. Update rules update the data into the data target.
Types of Update rules:
Keyfigure:
- Source Keyfigure or Direct Mapping
- Formula: we use option to implement a formula by using Formula editor.
- Routine or Update routine: when use this option to transform the value of a key figure by using ABAP/4 code. When implementing an update routine we must refer to the fields by using the structure name as “COMM_STRUCTURE” i.e, [COMM_STRUCTURE-/BIC/PRICE]. When debugging the name of the update routine will be formed as ROUTINE_001.
- Routine with Unit: when use this option to transform the value of a key figure and also value of the unit characteristic associated with it by using ABAP/4 code
Characteristic:
- Source char or Direct Mapping
- Constant
- Master Data Attribute of: we use this option to feed value by doing lookup to the master data tables.
- Formula
- Routine
- Initial Value: Populates no value (by default NULL)
Time Characteristics:
- Source char or Direct Mapping (Automatic Time Conversion)
- Constant
- Master Data Attribute of: we use this option to feed value by doing lookup to the master data tables.
- Formula
- Routine
- Initial Value: Populates no value (by default NULL)
- Time Distribution: we use the option to distribution values from Higher level Time characteristics to Lower level Time characteristics.
Start Routine:
- Start routine is executed before individual update rules.
- Start routine is executed packet by packet.
- So we use start routine to perform or implement any kind of logic which is supposed to get executed before update rules.
- When implementing start routine we use an INTERNAL TABLE – DATA_PACKAGE.
- Sample code:
LOOP AT DATA_PACKAGE.
IF DATA_PACKAGE-/BIC/ZCREG <> ‘AMR’.
DELETE DATA_PACKAGE.
ENDIF.
ENDLOOP.
Return Table:
We use this option when we want to split one record from the source to multiple records in the data target.
Difference between Update rules & Transfer rules:
Transfer Rules
|
Update Rules
|
Transfer Rules will just Transfer the data
|
Update Rules will update the data into data target
|
Transfer rules are specific to source system
|
Update rules are specific to Data Target.
|
Different Data flow Designs:
- One InfoSource to Multiple Data Target – Yes
- Multiple InfoSource to Single Data Target – Yes
- One InfoSource can be assigned with multiple DataSources – yes
- Same DataSource cannot be assigned to multiple InfoSources
Master Data:
Detailed Information about any Entity is called as Master Data.
Ex:- Detailed information about a customer – Customer Master data
In SAP BW, we have 3 types of Master data:
- ATTR
- TEXT
- HIER
ATTR: is used store all the attributes / properties of an entity.
Text: is used to store all the descriptions in different languages
HIER: is used to store parent-child data
How to load Master data ATTR & TEXT from Flatfile
Steps:
- Create the Application component
- Create the Info Source of type Direct Update
- Assign the DataSource to InfoSource
- Activate the Transfer rules for ATTR & Text DataSources
- Create the Info Packages and schedule the loads
Note:- we need to create one Infopackage for ATTR DataSource and one for Text DataSource
Hierarchies:
When do we go for hierarchies:
When the Characteristics are related as 1:M and in the Reporting if we need to display the values by using hierarchies (Tree like display)
Types of Hierarchies:
- Hierarchy Not Time dependent

- Hierarchy Structure Dependent on Time
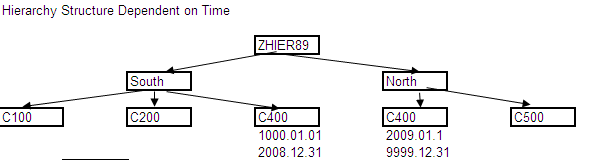
- Entire Hierarchy Dependent on Time

- How to load Hierarchy from the flat file?
Steps:
- Create the Info Source
- Assign the Data Source
- Create the file as per the Hierarchy
- Create the Infopackage and schedule the load
Reference & Template:
Reference
If we have an info object 'A', when we create the Info object 'B' by taking 'A' as the reference, all the properties of 'A' are copied towards 'B' and we cannot change any properties to 'B', We cannot load any data to the info object 'B' but it refers to the data / data dictionary tables of main info object 'A'.
Template
If we have an info object 'A', when we create the Info object 'C' by taking 'A' as the Template, all the properties of 'A' are copied towards 'C' and we can change the properties of 'C', we can load the seperate master data for the info object 'C'.
When do we go with reference:
When we want to create the new master data object which is supposed to hold the data which is already a sub set of some other Master data objects, we go for creating the Master data object with reference.
Reference Example:-
- Sold to Party , Ship to Party, Bill to Party, Payer are created with reference to Customer.
- Sende r Cost Center and Reciever Cost Center are created with reference to Cost Center.
Converting Master Data as Data Target:
ODS
- ODS: (Operational Data Store)
- ODS is also an Info Provider like Info Cube.
- ODS is a 2 dimensional.
- the Property of ODS is : Overwrite.
- We perfer ODS to do detailed level of reporting
- we also use ODS for Staging.
ODS CONTAINS 3 TABLES:-
- New Data Table
- Active Data Table
- Change Log
1. Active Data Table:
- /BIC,0/AXXXXXX00
- Structure: - All Key Fields [Primary Key]+ All data Fields + Recordmode
- Reporting
- Active data table will be the Source when we schedule Init / Full update for Data Mart
2. New data Table:
- /BIC,0/AXXXXXX40
- - Structure: - Technical Keys [loading Request No + Data packet no + Record No] (Primary Key) + All Key Fields + All data Fields + Recordmode
- - First table where the data is staged in ODS.
3. Change Log Table:
- - /BIC/B000*
- - Structure: - Technical Keys [Activation Request No + Data packet no + Record No + Partin no] (Primary Key) + All Key Fields + All data Fields + Recordmode
- - Registry of all the changes in the ODS.
- - Change log table will be the Source when we schedule Delta update for Data Mart
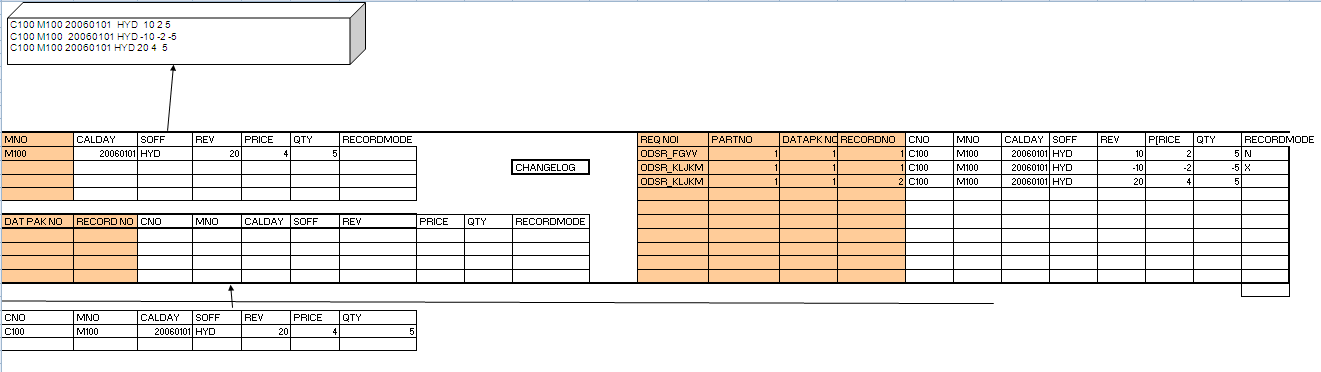
Points to be noted:
- when we design a report on the ODS, it fetches data from the active data table.
- When we load data from ODS to info cube with "Full update / Initialize delta update", it takes the data from Actve data table of the ODS.
- When we load data from ODS to info cube with "Delta update", it takes the data from Change log table of the ODS.
- Note : Max no. of Key fields : 16
- We cannot use keyfigures in the Key fields.
How does the overwrite functionality works by using thes tables:
when we load data into ODS, initially the data is loaded into New Data table. By using "Set quality status to OK" we convert the request status from yellow to green. once the request status is green we "Activate the DATA in ODS" - It delets the records in the new Data table and then moves the records from new Data table to Activa data table by overwriting the records if it finds the records with the same key field combination and maintains respective entries in change log table.
- How to create the ODS?
- How to load data into ODS from Flat file ?
Pre-requisites:
1) Flat file source system connection should be ready
2) Flat file should be ready
Steps:-
- Create the Application Component
- Create the Info Source - [ flexible update ].
- Assign the Data Source to Info Source
- Connect ODS to the Info Source with Update rules.
- Create the info package and run the load.
- Deleting Data
1) Delete Data
- It deletes all the contents in all the three tables.
2) Deleting based on a Request
- It deltes data in all the tables .
- When we delete a request in a ODS it deletes the selected request and all the requests above it.
3) Selective Deletion
- When we want to delete the records in the ODS based on the values of a particular Characteristic.
- It Deletes data only in Active Data Table.
4) Delete Change log Data
- It deletes data only in the change log table based on the request (no of days, before particular date).
- Condensing / Donot condense into Single reguest
- When we are activating multiple request in a ODS at a time, if we select the option "DO NOT CONDENSE THE REQUEST INTO WHEN ACTVATION TAKES PLACE", each request will have its own Activaion request. if you dont select the option "DO NOT CONDENSE THE REQUEST INTO WHEN ACTVATION TAKES PLACE", all the request will have the same activation request. So if we delete a particular request, it deletes all the other request in the ODS with the same Activation reuest.
- Activation Serially / Parallel
Data Marts:
Case 1:
Loading Data from ODS to Info Cube
Pre-requisites:
1) Myself Source System Connection
2) Application Component - Data Mart (DM)
Steps:
1) Identify the Source object and the Target Object.
SO - yo_sd01
TO - yc_dm1
2) Check whether the Source Object has got the "EXPORT GENERATE DATA SOURCE". If it is not there we have to explicitly generate the "EXPORT GENERATE DATA SOURCE".
SO - yo_sd01 - EGDS - 8yo_sd01
3) Connect the Source object to the Target Object with the help of Update rules.
4) Find the Info source which gets created automatically when we build the update rules and this Info source is also assigned with Myself source system connection under the Application Component (Data Marts).
5) Create the Info Package and Schedule the load.
Case 2:
Loading Data from Info cube to Info Cube
Pre-requisites:
1) Myself Source System Connection
2) Application Component - Data Mart (DM)
Steps:
1) Identify the Source object and the Target Object.
SO - yc_dm1
TO - yc_dm2
2) Check whether the Source Object has got the "EXPORT GENERATE DATA SOURCE". If it is not there we have to explicitly generate the "EXPORT GENERATE DATA SOURCE".
3) Connect the Source object to the Target Object with the help of Update rules.
4) Find the Info source which gets created automatically when we build the update rules and this Info source is also assigned with Myself source system connection under the Application Component (Data Marts).
5) Create the Info Package and Schedule the load.
- How to correct the Delta Load ?
- Different Update Mechanisims to different Data Targets?
In case of ODS : we cannot do a "Full update" after doing "INIT" or "DELTA" updates because this will reset the Delta Management of the ODS. So to overcome with this problem we use "Repair Full Request".
In case of ODS : When we already have the full updates done to the ODS, The ODS will Not accept to load data with "INIT and DELTA updates" . So by using the Function Module - "RSSM_REQUEST_REPAIR_FULL_FLAG" we convert all the request with "FULL UPDATE" in the ODS to "REPAIR FULL REQUEST".
Reporting:
- BEx (Business Explorer)
- Query Designer:
- To Design BEx Queries.
- Analyzer
- To Design the BEx Workbooks
- WAD:
- To Design Web Templates by using Web Items.
- BEx Query Designer:
- Data Target...?
- Info Provider...?
- How to Design a Simple Query?
- Query Execution Process?
When we execute the BEx query it triggers the OLAP Processor and this identifies the Info Cube on which the BEx report should be executed on and triggers the query on to the Info Cube and selects the records and aggregate the records based on the Characteristic Values in the OLAP Processor and transfers the records to the Front end (BEx) and the records are formatted in the Frontend.
- How to see SQL statement?
By using the T-code RSRT
- Characteristic Properties:
- Key figure Properties:
- Query Properties:
- Restriction:
- when we want to restrict the output of the query based on the values of a characteristic.
- Conditions:
- When we want to restrict the output of the Query based on the value of a Key figure.
- Switch on / off
- Active
- All Char / Individual Char
- We can have multiple conditions in a report.
- When we build a condition with multiple restrictions in it - it plays with OR and when we build multiple conditions with each of the restrictions in it - it plays with AND.
- Scenarios
- Top 10 Customers
- Top 10 Products
- List of all the Purchase orders with Purchase order value < 500 k Dollars
- Exceptions:
- We use Exceptions to provide alerts on to the Report based on the key figure value.
- - Active
- - Cell Restriction
- - Degrades Query performance
- - Scenario
- - We have used exceptions to provide alerts in the - P/A Report - only on the result.
- - Designing Score Card Report
- Restricted Key figure:
- - When we want to restrict a particular keyfigure based on the value of a characteristic.
- - Restricted Key figure is Global at the Info Provider Level
- New Selection
Diff. between Restricted Key figure / New Selection
- RKF is Global / New selection is Local
- Calculated Key figure:
- When ever we want to calculate a new keyfigure based on the existing key figures by using some functions by SAP.
- New Formula:
Diff. Between Calculated Keyfigure / New Formula
- CKF is Global / New formula is Local
- CKF can use all the keyfigures in the cube / New formula can only use the key figures which are acting as the Structure elements.
- New formula has 6 functions more when compared with CKF
- Structures:
---------------
- - It acts as a Reusable Component
- - Local / Global
- - Remove Reference
- - Max no of a Query - 2
- - We can use Structures to provide Level up - Level Down Effect by using New Seletion Nodes.
- - GL Account - FI Reports
- Cell Definitions:
- Table Dispaly:
- - Enabled only when we dont use 2 structures in a report
- - When we want to mix up the display of the Cha.. and Key figures.
- Variables:
- We use variables to parameterize the queries
- Types of Variables:
- - Charecteristic Value Variable
- - Text Variable
- - Formula Variable
- - Hierarchy Variable
- - Hierarvhy Node Variable
- Processing Types:
- - User Entry / Default
- - Customer Exit
- - SAP Exit
- - Replacement Path
- - Authorization
- Case 1: Charecteristic Value Variable with User Entry / Default:
--------------------------------------------------------------------------
Example 1:
--------------
- Variable Offset
- Case 2: Charecteristic Value Variable with Replacement Path-
---------------------------------------------------------------------------
we use this when we want a Charecteristic Value Variable to be replaced with query result set of the other query.
- RRI
------
- RSBBS
- Case 3: Charecteristic Value Variable with SAP Exit:
--------------------------------------------------------------
All Business content variables will have the processing type as SAP Exit.
- Case 4: Charecteristic Value Variable with Authorization:
---------------------------------------------------------------------
Steps:
--------
1. Enable the Info Object as Authorization Relevant - RSA1.
2. Create the Authorization Object - RSSM.
3. Check the Authorization Object on the Info Provider - RSSM.
4. Create the roles & generate the profiles- PFCG
5. Create the users - SU01
6. Go to BEx Query Designer, create a Charecteristic Value Variable with Authorization processing type on the Info Object.
- Formula with Replacement Path:
----------------------------------------
- we also use Formula with Replacement path, to replace the key figure attribute of a characteristic.
0mat_plant - Standard Price * Sales Qty ( Sales cost )
- Hierarchy variable:
------------------------
- User Entry / Default - 80%
- Customer Exit - 20 %
- SAP Exit
- Case 1: Hierarchy variable with User Entry / Default:
-----------------------------------------------------------------
- Hierarchy Node Variable:
------------------------------
- User Entry / Default - 80%
- Customer Exit
- SAP Exit
- Authorization - 20 %
- Customer Exit:
-------------------
- To populate a value to the variable by implementing ABAP/4 code.
- We use an enhancement RSR00001
- SMOD
- Case 1:
----------
Characteristic Value Variable with Customer Exit:
------------------------------------------------------
- 0CALDAY - with Customer Exit - Current Date
- Steps:
---------
1. In the BEx Query Designer. create a Characteristic Value Variable with Customer Exit on 0CALDAY.
2. Implement the ABAP/4 code to populate value into this variable.
2.1) Create a Project - CMOD.
2.2) Assign the Enhancement - RSR00001 to the project - CMOD.
2.3) Check the Components - CMOD
2.4) Implement the ABAP/4 code in the Function Exit - CMOD.