
How to Do Partitioning
What is Partitioning?
Partitioning splits up the whole dataset for an Info-Cube into several, smaller, physically independent and redundancy-free units.
There are two different ways of Partitioning:
- Physical partitioning:
- This is done to improve the query performance with the cube and has to done after the cube has been created and before data has been loaded into the cube. This type of partitioning is also called as “Range Partitioning”.
- Logical Partitioning:
- Partitioning on the basis of specific criteria and create new independent structure. For eg : one cube will be split into multiple cube on some criteria(eg Fiscal year) as per business requirement.
What is the use of Partitioning?
Improves the reporting performance and data deletion from the cube.
What are the pre-requisites for Partitioning?
Partitioning can be implemented using time info-object only. The two info-objects that can be used for partitioning are calender month(0CALMONTH) and fiscal year/period(0FISCPER). Hence the cube must contain atleast one of the two info-objects.
Let us consider an example to demonstrate partitioning using 0CALMONTH….
Here the Cube ‘ ZPARTI’ is partitioned with 0CALMONTH before any data load, Customer and Purchasing Unit and the option for creating Partitions is shown below….
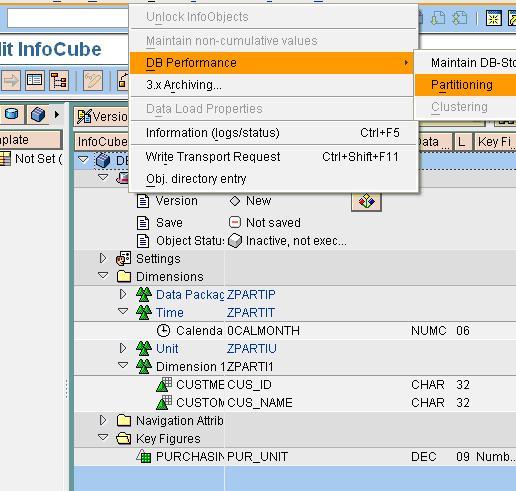
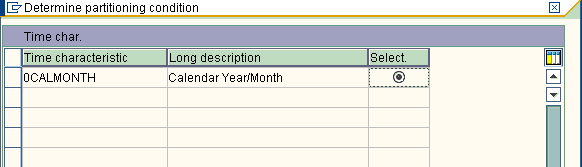
2 years * 12 months + 2 = 26 partitions are created ( 2 partitions that lie outside the range that is before 01.2006 and after 12.2007).Say for example we choose 10 partitions…
Now the system summarizes every 3 months into a partition ( that is one partition corresponds to excatly one quarter), therefore 2 years * 4 partitions/year + 2 marginal partitions = 10 partitions are created on the database.
Now enter the inputs as per the above calculation….
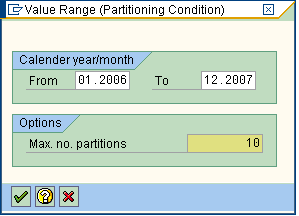

Output in RSDCUBE....

The concept of re-partitioning is useful if we have already loaded the data into the cube with follwing one of the following steps…
a) If we did not create the partition when we have created it.
b) We have loaded more data into the cube than what we have partitioned.
c) If we did not choose long enough time for partitioning
d) Some partitions may contain less data or no data due to data archiving over certain period.
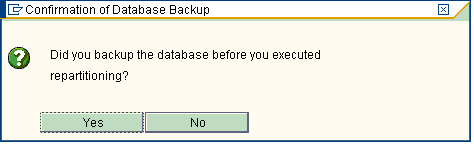
Note: It always recommended taking data backup before doing re-partitioning.
Info cube partitions are either merged at the bottom or added at the top.
If we want to merge the partitions which are empty or no data has been loaded outside of the time period initially defined. In this case the runtime takes only a few minutes. If there is data in the partitions in which we want to merge or if data has been loaded beyond the time period than initially defined, then the system will save the data in a shadow table and then copies it to original table. Here the runtime depends on the amount of data the system has to copy.
We can also merge and add partitions for aggregates as well as cubes and we can reactivate all the aggregates after the cube has been changed.
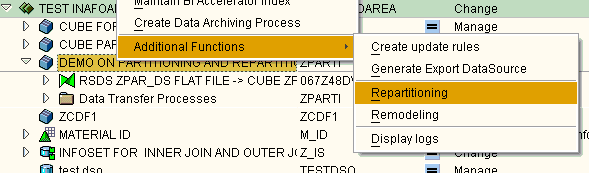
We can start re-partitioning by right clicking on the cube and selection Repartitioning option as shown….

As mentioned before it is recommended to take a backup before repartitioning as shown….

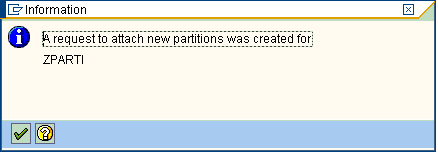
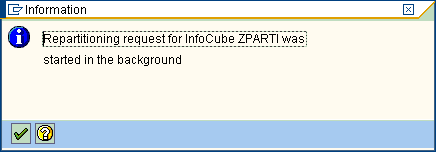


Logical partitioning
This method is used if your data in your cube become huge. So you create multiple cubes say for 1cube for 2001, another cube for 2002, etc... You can then use a multiprovider - which consists of all these cubes and then report on all the data.

For eg a Single cube can be separate on fiscal year basis.
Refer below screen shot which shows Financial COPA cube being separated into multiple cubes based on fiscal year.
The advantage of this method is we are allowed to keep different parameters for separating depending on business requirement and reporting layer requirements.
Disadvantages are increase in no of objects manages in the landscape.